Adaptive request concurrency. Resilient observability at scale.
Improving reliability and performance across your entire observability infrastructure

Observability pipelines have become critical infrastructure in the current technological landscape, which is why we’ve built Vector to provide extremely high throughput with the tiniest resource footprint we can manage (Rust is a huge help here). But this is not enough in the real world: your observability pipeline needs to provide optimal performance and efficiency while also being a good infrastructure citizen and playing nicely with services like Elasticsearch and Clickhouse.
And so we’re excited to announce that Vector version 0.11 includes support for Adaptive Request Concurrency (ARC) in all of its HTTP-based sinks. This feature does away with static rate limits and automatically optimizes HTTP concurrency limits based on downstream service responses. The underlying mechanism is a feedback loop inspired by TCP congestion control algorithms.
The lead-up
One of the most common support questions we get about Vector involves logs like this:
TRACE tower_limit::rate::service: rate limit exceeded, disabling service
Users typically have two questions about this:
- What does it mean?
- How can I fix it?
The answer to the first question is simple: Vector has internally rate-limited processing to respect user-configured limits—request.rate_limit_duration_secs and request.rate_limit_num—for that particular sink. In other words, Vector has intentionally reduced performance to stay within static limits.
The answer to the second question—how to fix it—is more complex because it depends on a variety of factors that change over time (covered in more detail below). Telling the user to raise their limits would be irresponsible since we’d then risk overwhelming the downstream service and causing an outage; but not changing them could mean limiting performance in a dramatic way.
The crux of the matter is that Vector’s high throughput presents a major challenge for HTTP-based sinks like Elasticsearch because those services can’t always handle event payloads as quickly as Vector can send them. And when data services are heavily interdependent—which is almost always!—letting Vector overwhelm one of them can lead to system-wide performance degradation or even cascading failures.
In versions of Vector prior to 0.11, you could address this problem by setting rate limits on outbound HTTP traffic to downstream services. Rate limiting certainly does help prevent certain worst-case scenarios but customer feedback and our own internal QA has revealed that this approach also has deep limitations.
The problem: rate limiting is not a panacea
Rate limiting is nice to have as a fallback but it’s a blunt instrument, a static half-solution to a dynamic problem. The core problem is that configuring your own rate limits locks you into a perpetual loop:
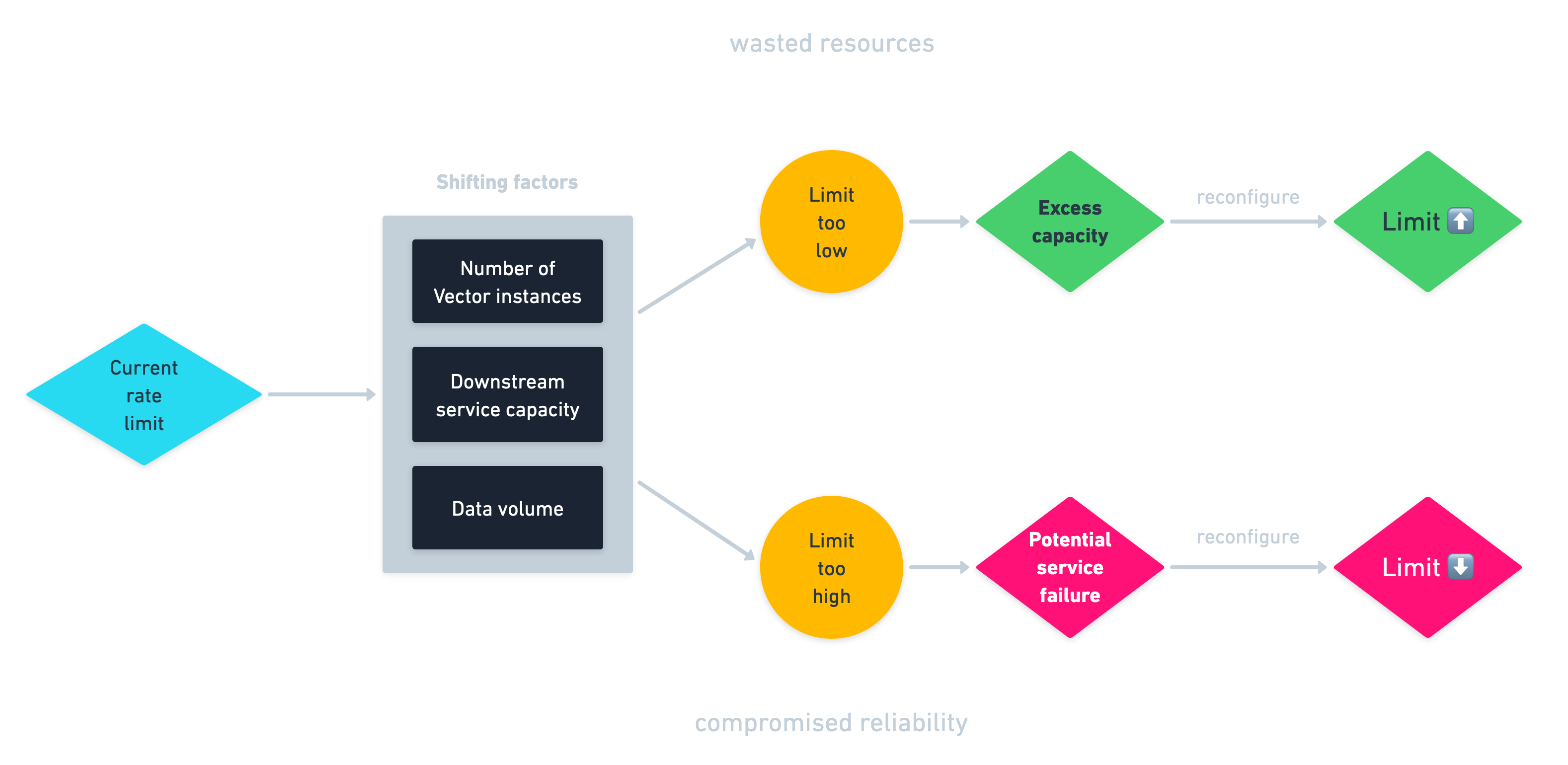
Within this vicious loop, you need to constantly avoid two outcomes:
- You set the limit too high and thus compromise system reliability by overwhelming your services. Time to lower the limit and re-assess.
- You set the limit too low and waste resources. Your Elasticsearch cluster may be capable of handling more concurrency than you’re providing—at least for now. Time to raise the limit and re-assess.
Not only do you need to perform this balancing act on a per-sink basis and on each Vector instance—that may be a lot of application points in your system—but the optimal rate is an elusive target that shifts along with changes in a number of factors:
- The number of Vector instances currently sending traffic
- The current capacity of downstream services
- The volume of data you’re currently sending
These changes are especially pronounced in highly elastic environments, like Kubernetes, that are essentially designed to let you tweak cluster topologies, configuration, and much more with very little friction, which compounds the problem.
And don’t forget, of course, that this chasing-the-dragon decision loop has its own cognitive and operational costs.
The solution: Adaptive Request Concurrency
We feel strongly that Vector’s Adaptive Request Concurrency (ARC) feature provides a qualitatively better path than rate limiting. With ARC enabled on any given sink, Vector determines the optimal network concurrency based on current environment conditions and continuously re-adjusts in light of new information.
Here’s how that plays out in some example scenarios:
| Change | Response | |
|---|---|---|
| You deploy more Vector instances | ➔ | Vector automatically redistributes HTTP throughput across both current and new instances |
| You scale up your Elasticsearch cluster | ➔ | Vector automatically increases concurrency to take full advantage of the new capacity |
| You scale your Elasticsearch cluster back down | ➔ | Vector lowers concurrency to avoid any risk of destabilizing the cluster (while still taking full of advantage of the now-decreased bandwidth) |
| Your Elasticsearch cluster experiences a temporary outage | ➔ | Vector lowers concurrency dramatically and provides backpressure by buffering events |
With ARC, these scenarios require no human intervention. Vector quietly hums along making these decisions for you with a speed and granularity that rate limits simply cannot provide.
How it works
ARC in Vector is based on a decision-making process that’s fairly simple at a high level. When Vector POSTs data to downstream services via HTTP, it continuously keeps track of downstream service performance and uses that information to make precise concurrency decisions.
The diagram below shows Vector’s decision chart:
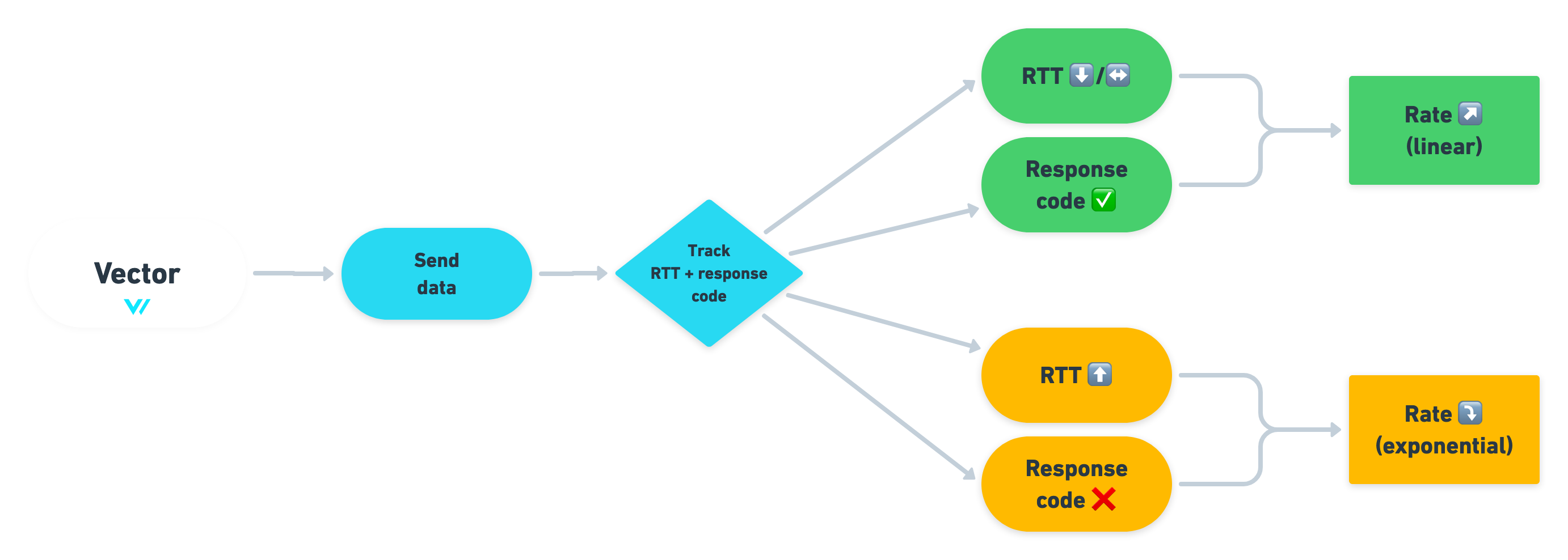
With ARC enabled, Vector watches for significant movements in two things: the round-trip time (RTT) of requests and HTTP response codes (failure vs. success).
- If the RTT is declining/constant and/or response codes are consistently successful (200-299), Vector sees 🟢 and increases the throughput linearly. This is the “additive increase” in AIMD.
- If the RTT is increasing and/or response codes consistently indicate failure—codes like
429 Too Many Requestsand503 Service Unavailable—Vector sees 🟡 and exponentially decreases concurrency. This is the “multiplicative decrease” in AIMD.
This decision tree is always active and Vector always “knows” what to do, even in extreme cases like total service failure.
The role of configuration
Vector never stops quietly making the linear up vs. exponential down decision in the background, and it works out of the box with zero configuration beyond enabling the feature, which is currently on an opt-in basis in version 0.11. You can enable ARC in an HTTP sink by setting the request.concurrency parameter to adaptive. Here’s an example for a Clickhouse sink:
sinks:
clickhouse_internal:
type: "clickhouse"
inputs: ["log_stream_1", "log_stream_2"]
host: "http://clickhouse-prod:8123"
table: "prod-log-data"
request:
concurrency: "adaptive"
There’s also room for fine-tuning if you find yourself needing additional knobs:
- Buffering. What happens when Vector needs to lower concurrency and thus throttle the output? What happens to data that needs to be sent later? Vector lets you choose between an on-disk and an in-memory buffer and to set a max_size for that buffer. The
memorybuffer is the default, which maximizes performance, but you can always choosediskif your use case requires stronger durability guarantees. As always, this can be configured on a per-sink basis. - The adaptive concurrency algorithm itself. In general, you shouldn’t need to adjust the algorithm, but in case you need to resort to that, there are three parameters available:
decrease_ratio— This determines how rapidly Vector lowers the limit in response to failures or higher latency.ewma_alpha— Vector uses an exponentially weighted moving average (EWMA) of past RTT measurements as a reference to compare with the current RTT. Theewma_alphaparameter determines how heavily new measurements are weighted compared to older ones.rtt_threshold_ratio— The minimal change in RTT necessary for the algorithm to respond and adjust concurrency; changes below that threshold are ignored.
The defaults should work just fine for these parameters in most cases, but we know that some scenarios may call for a highly targeted approach.
How we built it
The development process behind ARC was highly methodical and data-driven. To summarize:
- Customer feedback has pinpointed concurrency management as a pain point since very early in the life of Vector.
- The initial foray in addressing the problem came in RFC 1858, which called for a qualitatively better option for users and gestured toward some possible inspirations.
- Our engineers ultimately opted for a solution deeply inspired by analogous work on the Netflix engineering team, which is beautifully summarized in the Performance Under Load piece on their blog. Our respective approaches utilize an additive-increase/multiplicative-decrease (AIMD) algorithm inspired by TCP congestion control algorithms. We’ll have a lot more to say about this here on the blog next week. If you want to see the in-depth discussion that drove this process, see GitHub issue #3255 on the Vector repo. There you’ll see a pretty epic back and forth within our engineering team along with a slew of visualizations. It’s quite the read.
- As Netflix is largely a Java shop and there was nothing immediately usable “off the shelf” in the Rust ecosystem, we needed to create our own Rust implementation, which you can see in the adaptive_concurrency module. Of special importance is the concurrency Controller, which is responsible for the linear up/exponential down decision that I alluded to above.
- For testing, the team mostly relied on our in-house http_test_server, a pretty straightforward but highly customizable HTTP server written in Go.
It took several months, some hefty PRs, and even a handful of dead ends, but we think that both the process and the end result are wholly consistent with the fastidious approach we strive for in building Vector.
More to come
Next week, we’ll follow up on this announcement with a post from Timber’s Bruce Guenter, the lead engineer behind ARC, that provides a far more in-depth look at how this feature was implemented. Bruce has quite an intricate story to tell and some great visualizations, so we urge you to tune in.
Going forward, we’ll continue listening to Vector users and incorporating their feedback on concurrency management into Vector’s roadmap. We’re fully open to refining the underlying algorithm and providing more configuration knobs in a future release if that serves our users. There’s currently an open issue, for example, that calls for exploration of an alternative gradient algorithm (also inspired by Netflix’s work), and some lively internal discussions are already pointing the way to next steps.
For now, we’re quite confident that ARC in Vector 0.11, even in its initial state, should immediately improve the experience of users that rely on downstream HTTP services.