Agent Architecture
Run Vector at your edge to democratize processing.
Overview
This agent architecture deploys Vector as an agent on each node for local data collection and processing.
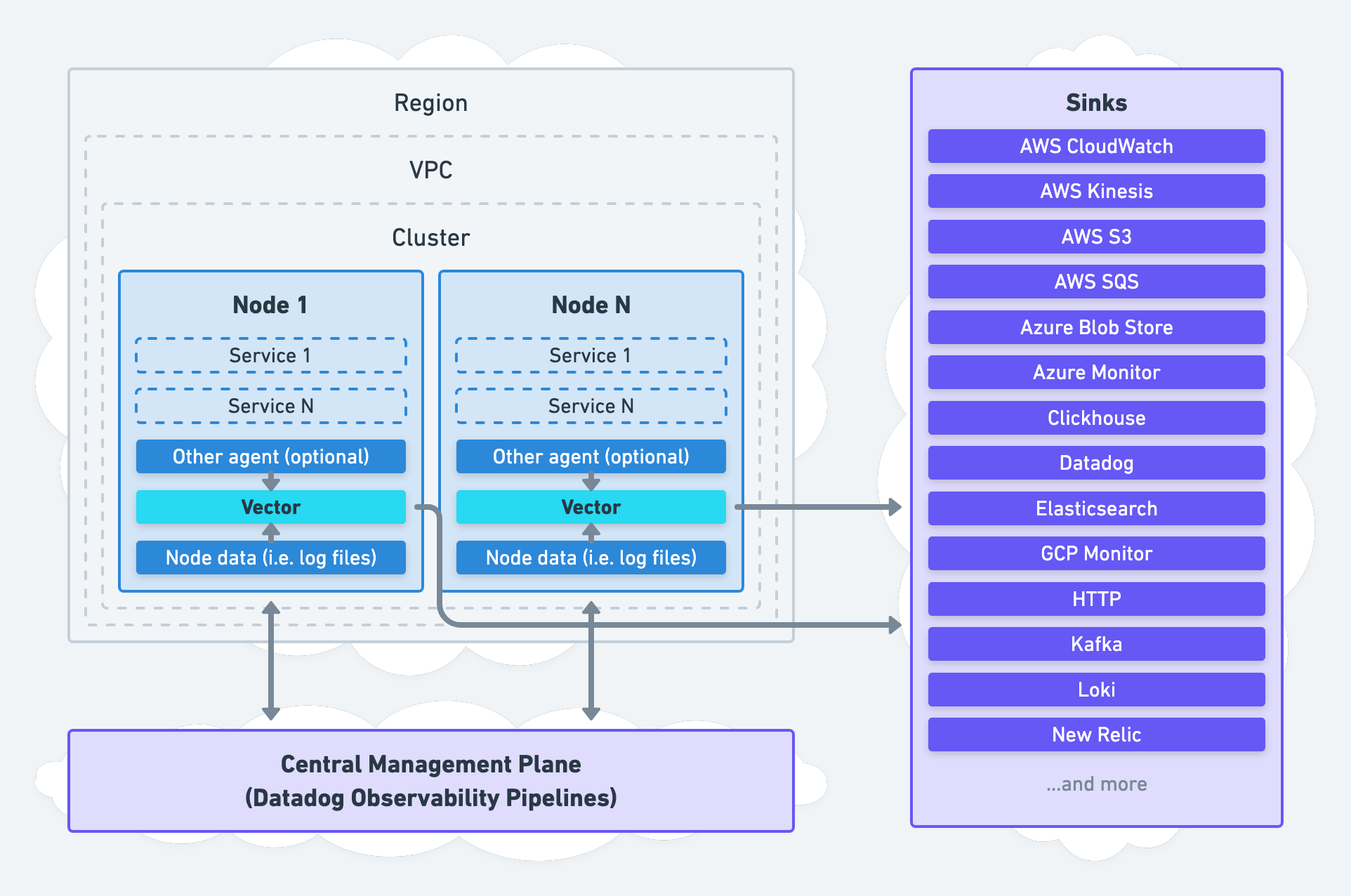
Data can be collected directly by Vector, indirectly through another agent, or both simultaneously. Data processing can happen locally on the node or remotely in an aggregator.
When to Use This Architecture
We recommend this architecture for:
- Simple environments that do not require high durability or high availability.
- Use cases that do not need to hold onto data for long periods, such as fast, stateless processing and streaming delivery. (i.e., merging multi-line logs or aggregating host specific metrics).
- Operators that can make node-level changes without a lot of friction.
If your use case violates these recommendations, consider the aggregator or unified architectures.
Going to Production
Architecting
- Only replace agents that perform generic data forwarding functions; integrate with all other agents.
- Limit processing to fast, stateless processing. If you need complex processing, consider the aggregator architecture.
- Limit delivery to fast, streaming delivery. If you need long-lived batching consider the aggregator architecture.
- Buffer your data in memory; do not buffer on disk. If you need durability, consider the aggregator architecture.
High Availability
- If the failure of a single Vector agent is unacceptable, consider the aggregator architecture, which deploys Vector across multiple nodes in a highly available manner.
- Enable end-to-end acknowledgements to mitigate data receive failures.
- Route dropped events to mitigate data processing failures.
Hardening
Sizing, Scaling, & Capacity Planning
- Limit the Vector agent to 2 vCPUs and 4 GiB of memory. If your Vector agent requires more than this, shift resource-intensive processing to your aggregators.
Rolling Out
- Roll out one network partition and one system at a time.
- Following the roll-out strategy and plan.
Advanced
Working with Other Agents
We recommend deploying Vector alongside other agents that integrate with specific systems and produce unique data. Otherwise, Vector should replace the agent. See the collecting data section for more detail.
Processing at the Edge
As a general rule of thumb, agents should not hold onto data. Furthermore, processing and delivery of data should be fast and streaming. If you need to perform complex processing or long-lived batching, use the aggregator architecture.
Support
For easy setup and maintenance of this architecture, consider the Vector’s discussions or chat. These are free best effort channels. For enterprise needs, consider Datadog Observability Pipelines, which comes with enterprise-level support.