Aggregator Architecture
Deploy Vector in your clusters to receive data from all your systems.
Overview
The aggregator architecture deploys Vector as an aggregator onto dedicated nodes for remote processing. Data ingests from one or more upstream agents or upstream systems:
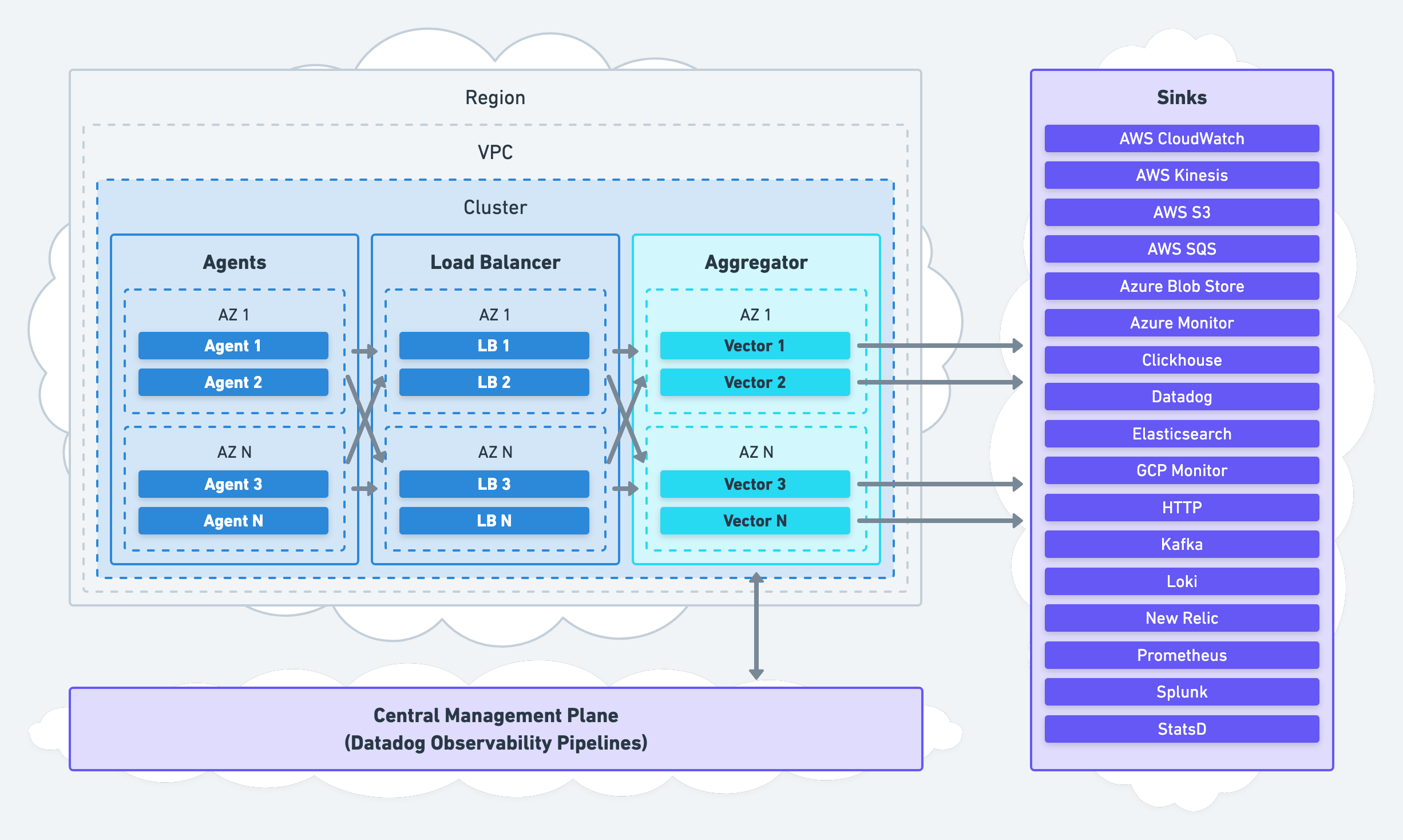
We recommend this architecture to most Vector users for its high availability and easy setup.
When to Use this Architecture
We recommend this architecture for environments that require high durability and high availability (most environments). This architecture is easy to set up and slot into complex environments without changing agents. It is exceptionally well suited for enterprises and large organizations.
Going to Production
Architecting
- Deploy multiple aggregators within each network boundary (i.e., each Cluster or VPC).
- Use DNS or service discovery to route agent traffic to your aggregators.
- Use HTTP-based protocols when possible.
- Use the
vectorsource and sink for inter-Vector communication. - Shift the responsibility of data processing and durability to your aggregators.
- Configure your agents to be simple data forwarders.
High Availability
- Deploy your aggregators across multiple nodes and availability zones.
- Enable end-to-end acknowledgements for all sources.
- Use disk buffers for your system of record sink.
- Use waterfall buffers for your system of analysis sink.
- Route failed data to your system of record.
Hardening
Sizing, Scaling, & Capacity Planning
- Front your aggregators with a load balancer.
- Provision at least 4 vCPUs and 8 GiB of memory per instance.
- Enable autoscaling with a target of 85% CPU utilization.
Rolling Out
- Roll out one network partition and one system at a time.
- Following the roll-out strategy and plan.
Advanced
Pub-Sub Systems
The aggregator architecture can deploy as a consumer to a pub-sub service, like Kafka:
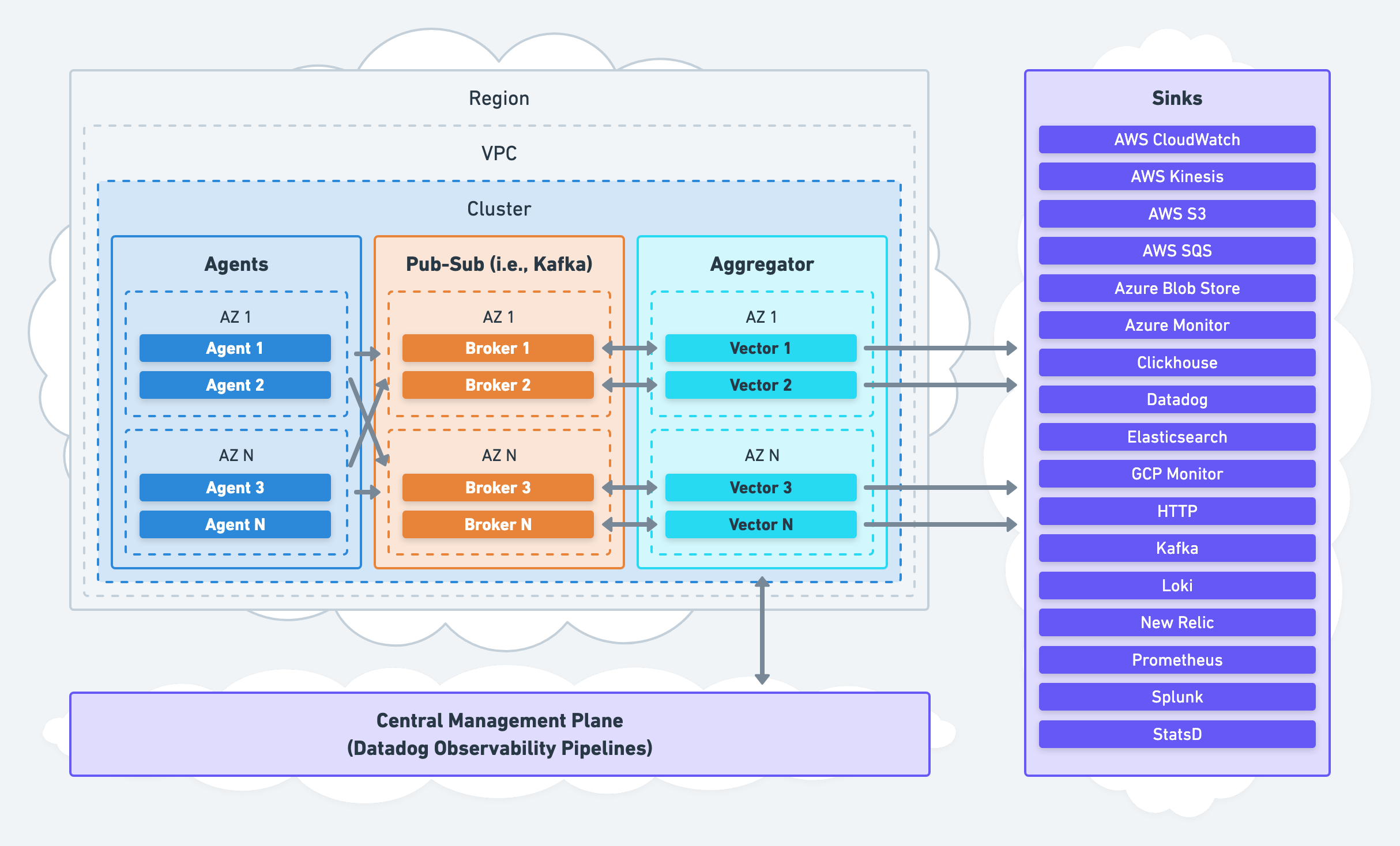
Partitioning
Partitioning, or “topics” in Kafka terminology, refers to separating data in your pub-sub systems. We strongly recommend partitioning along data origin lines, such as the service or host that generated the data.
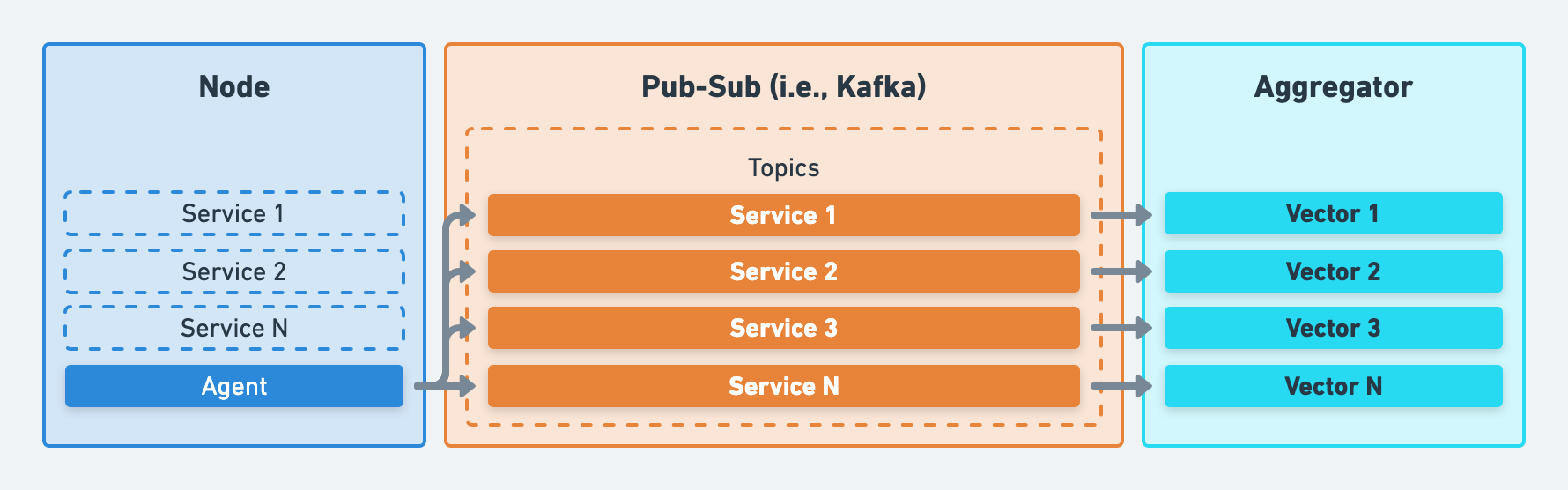
Recommendations
- Use memory buffers with
buffers.when_fullset toblock. This will ensure back pressure flows upstream to your pub-sub system, where durable buffering should occur. - Enable end-to-end acknowledgements for your Vector pub-sub source (i.e., the
kafkasource) to ensure data is persisted downstream before removing the data from your pub-sub systems.
Global Aggregation
Because Vector can be deployed anywhere in your infrastructure, it offers a unique approach to global aggregation. Aggregation can be tiered, allowing local aggregators to reduce data before forwarding to your global aggregators.
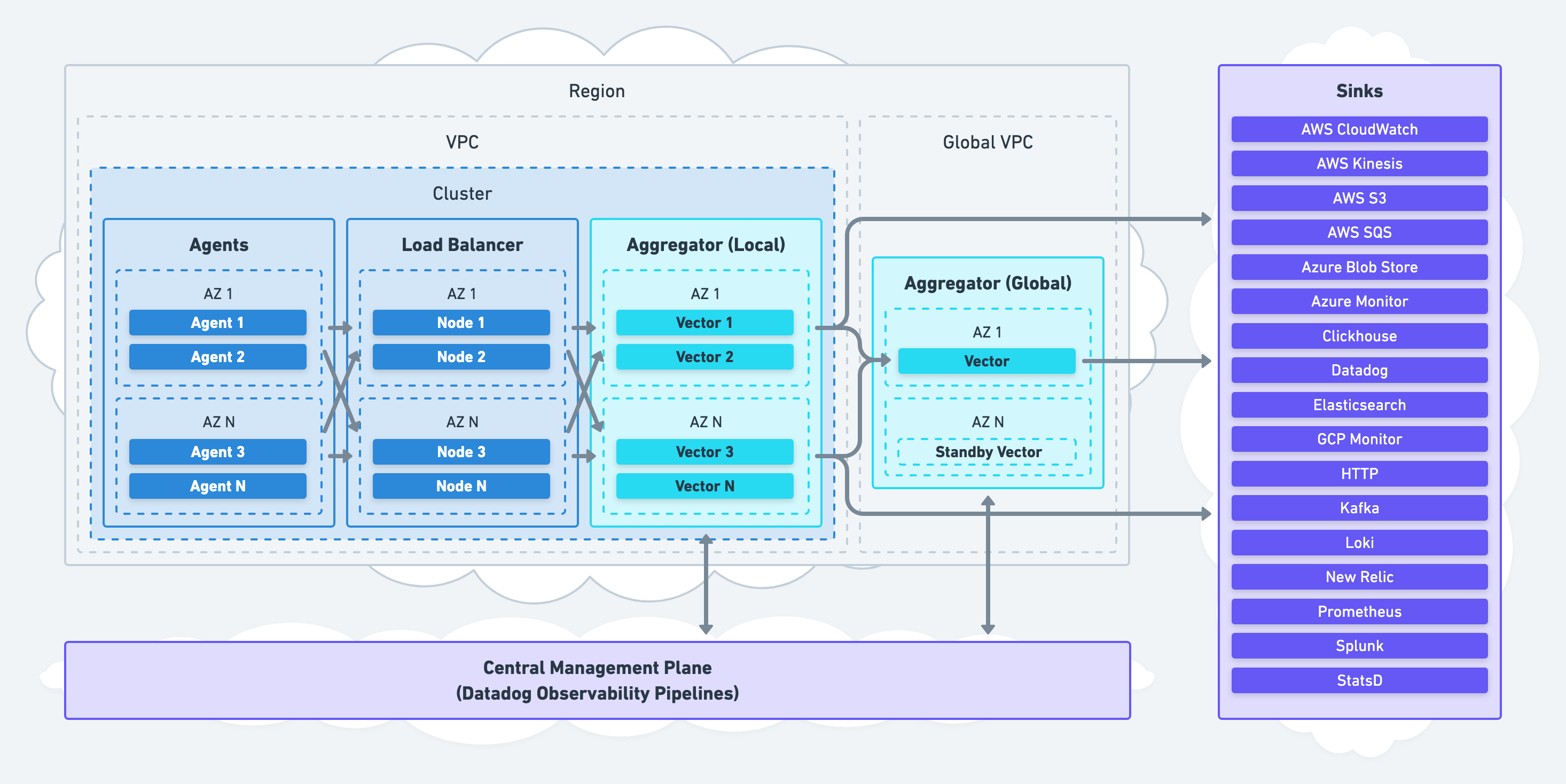
This eliminates the need to deploy a single monolith aggregator, creating an unnecessary single point of failure. Therefore, global aggregation should be limited to use cases that can reduce data, such as computing global histograms.
Recommendations
- Limit global aggregation to tasks that can reduce data, such as computing global histograms. Never send all data to your global aggregators.
- Continue to use your local aggregators to process and deliver most data. Never introduce a single point of failure.
Support
For easy setup and maintenance of this architecture, consider the Vector’s discussions or chat. These are free best effort channels. For enterprise needs, consider Datadog Observability Pipelines, which comes with enterprise-level support. Read more about Datadog Observability Pipelines.