Architecting your Deployment
Best practices for deploying Vector into production environments.
We’ll start with guidelines, discuss Vector’s role in your architecture, and end with how to design your pipeline.
Guidelines
1. Use the Best Tool for the Job
While Vector aims to help you reduce the number of tools necessary to build powerful observability pipelines, some tools may be better suited to the task at hand (i.e., the Datadog Agent for collecting data). Don’t hesitate to stick with other tools while adding Vector to your observability stack. Vector’s flexibility ensures that if the time comes to remove or replace certain tools from your stack, it can be done as seamlessly as possible.
2. Minimize Agent Responsibilities
To offset the risk of deploying different agents, agents should shift as much responsibility to Vector as possible. Agents should be simple data forwarders, performing only the task they do best and delegating the rest to Vector. This strategy minimizes your dependence on agents and reduces the risk of data loss and service disruption.
3. Deploy Vector Close to Your Data
Finally, Vector’s small footprint and shared-nothing architecture make it possible to deploy Vector anywhere in your infrastructure. To avoid creating a single point of failure (SPOF), you should deploy Vector close to your data and within your network boundaries. This not only makes your observability data pipeline more reliable but reduces the blast radius of any single Vector failure.
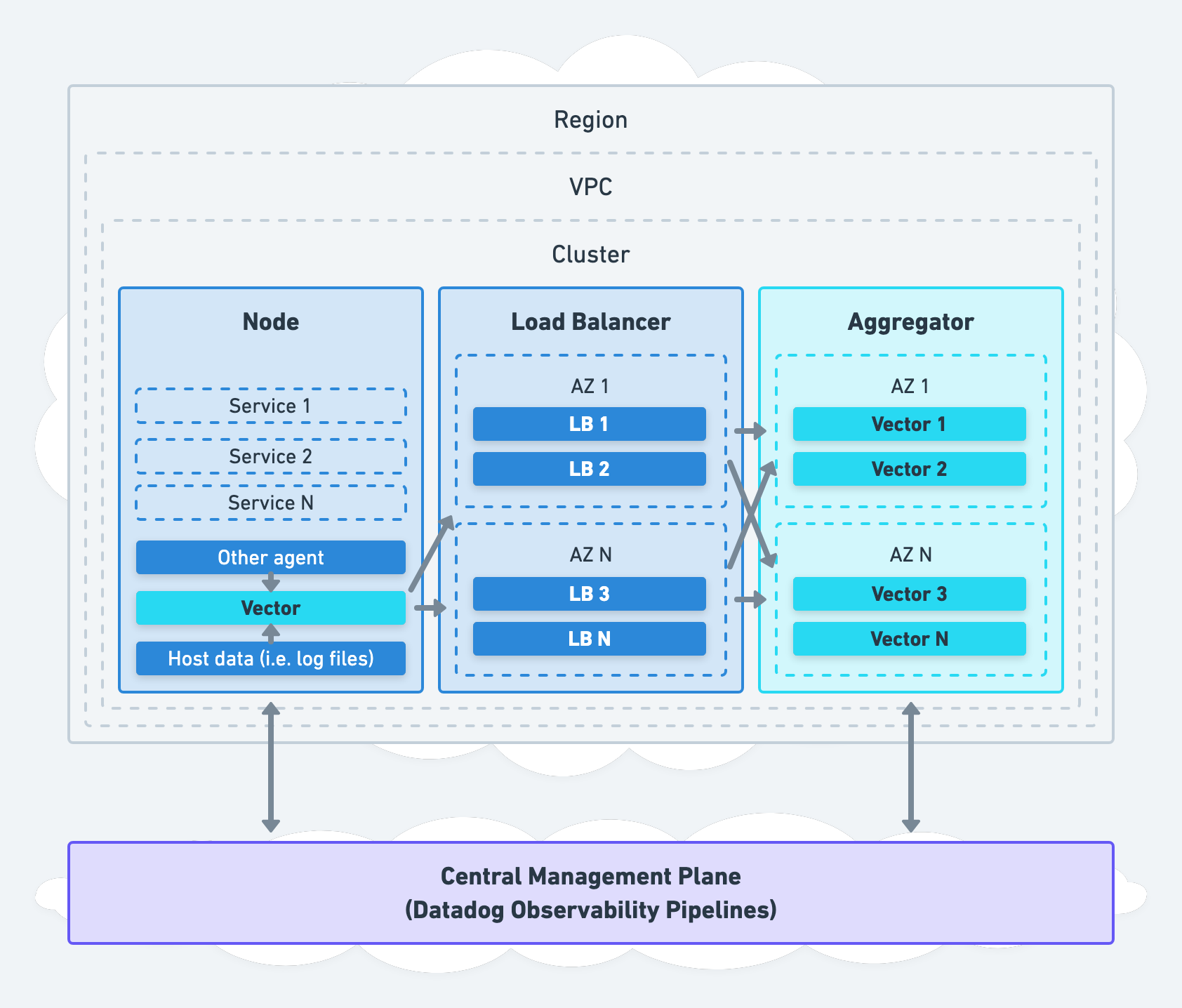
Vector’s Deployment Roles
Vector can deploy anywhere in your infrastructure, serving different roles. For example, it can deploy directly on your nodes as an agent or on its own nodes as an aggregator.
Agent Role
Vector’s agent role deploys Vector directly on each node for local data collection and processing:
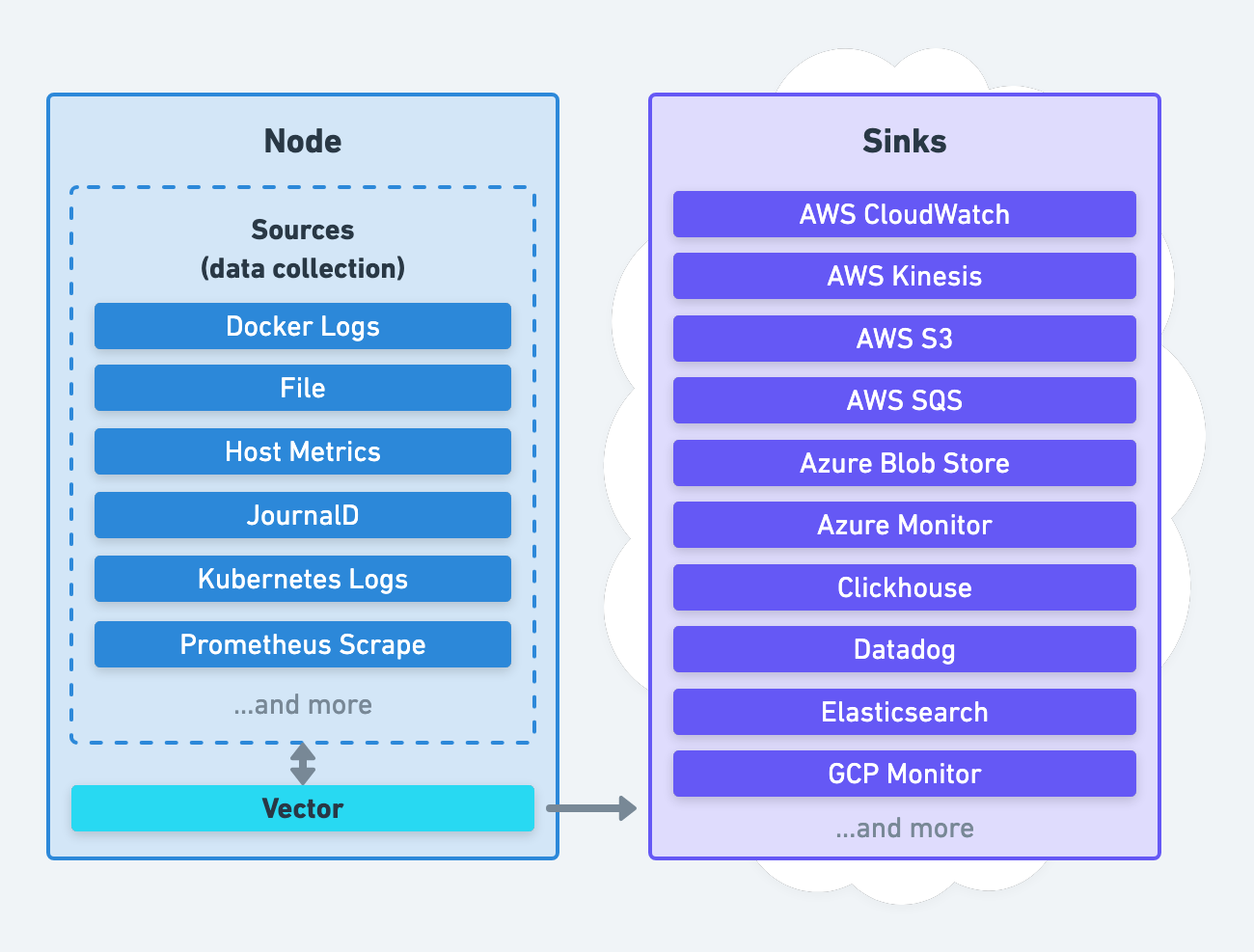
It can directly collect data from the node, indirectly through another agent, or both. Data processing can happen locally in the agent or remotely in an aggregator.
Aggregator Role
Vector’s aggregator role deploys Vector on dedicated nodes to receive data from upstream agents or pull data from pub-sub services:
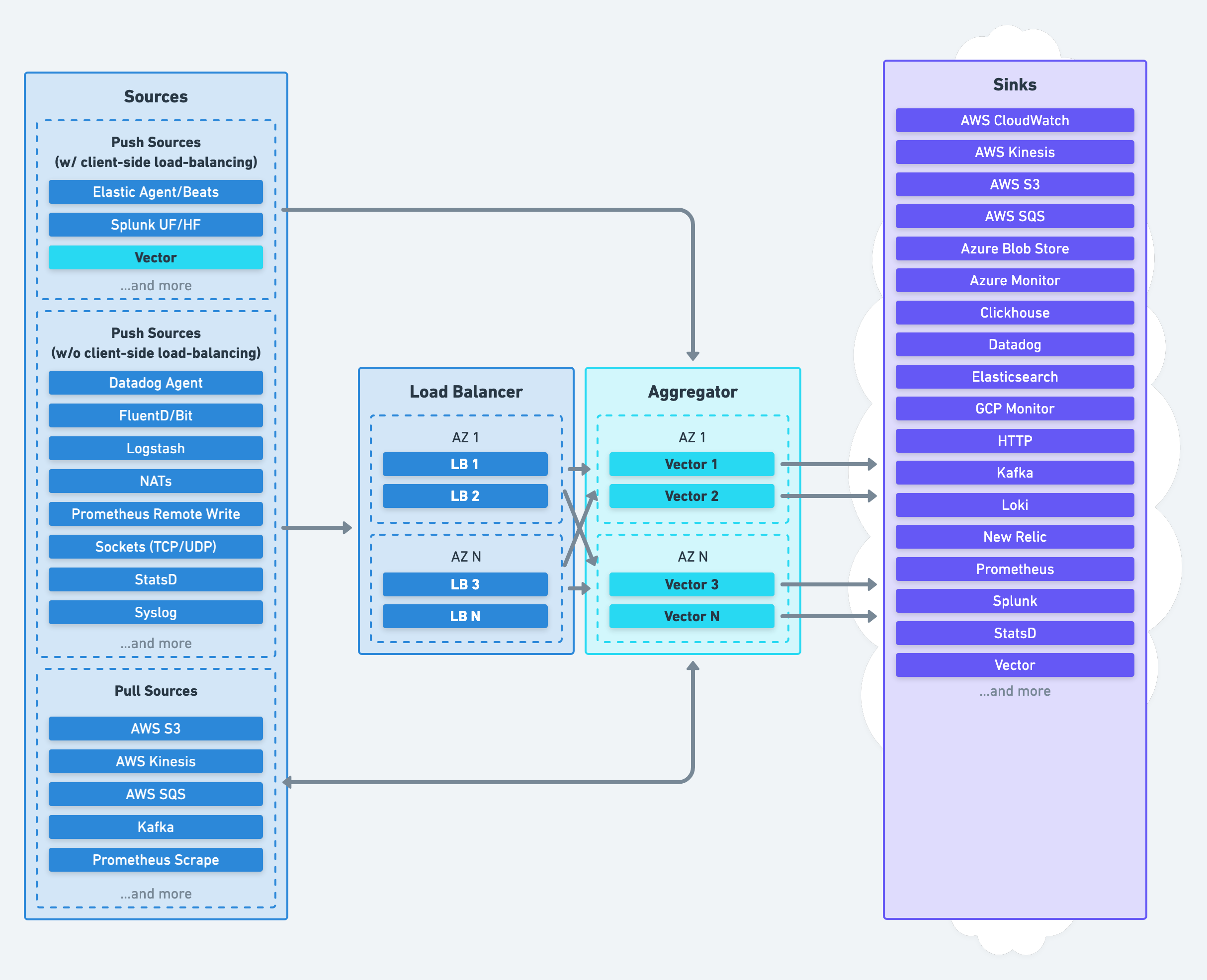
Processing is centralized in your aggregators, on nodes optimized for performance.
Design
Before we consider reference architectures, it’s helpful to understand the design characteristics used to form them. This helps you choose a particular architecture and tweak it to fit your unique requirements.
Networking
Deploying Vector raises several networking concerns, such as network boundaries, firewalls and proxies, DNS and service discovery, and protocols.
Working With Network Boundaries
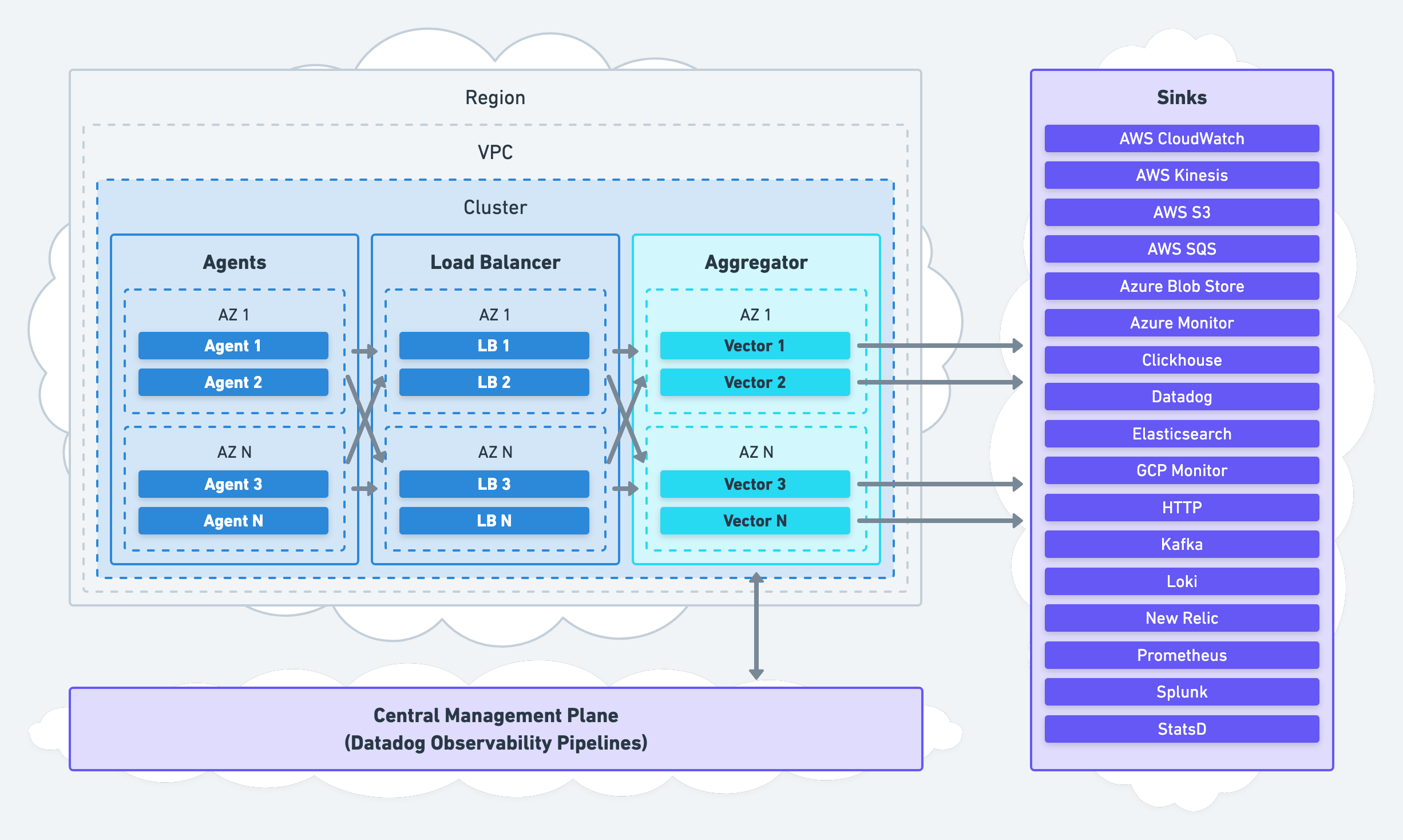
When deploying Vector as an aggregator, we recommend deploying within your network boundaries (i.e., within each cluster or VPC) across accounts and regions, even if this means deploying multiple aggregators.
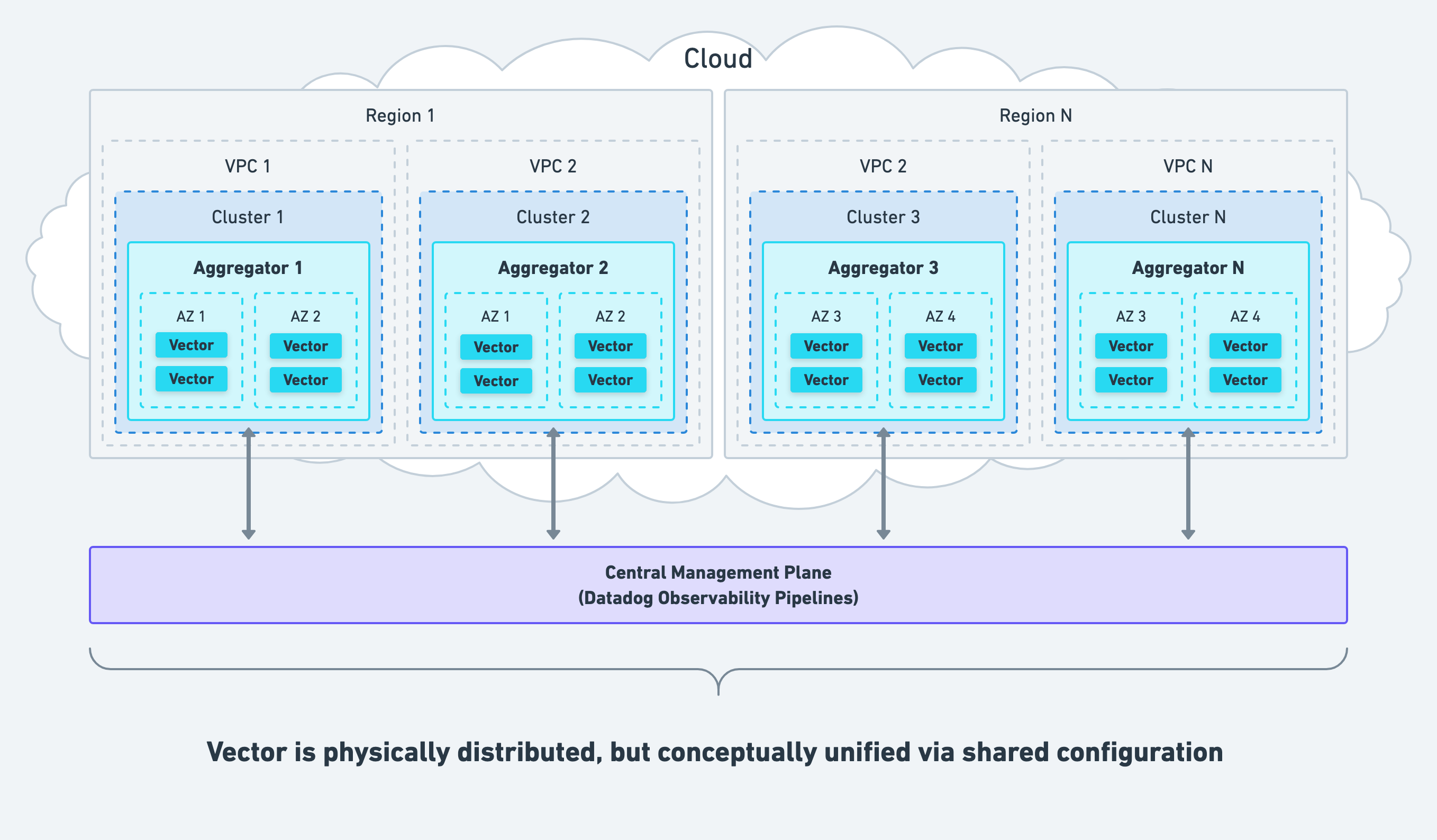
This strategy avoids introducing a single point of failure, allows for easy and secure internal communication, and respects the boundaries maintained by your network administrator. Management of Vector should be centralized for operational simplicity.
Even though Vector distributes physically across your infrastructure, it is conceptually unified via shared configuration. The same configuration can be delivered to all instances unifying them in behavior, acting as a single aggregator. Consider Datadog Observability Pipelines, Vector’s hosted control plane, for simplified management of multiple aggregators.
Using Firewalls & Proxies
We recommend following our network security recommendations. Restrict agent communication to your aggregators, and restrict aggregator communication to your configured sources and sinks.
For HTTP proxying, we do not recommend one way or another. However, if you prefer to use a HTTP proxy, Vector offers a global proxy option making it easy to route all Vector HTTP traffic through a proxy.
Using DNS & Service Discovery
Discovery of your Vector aggregators and services should resolve through DNS or service discovery.
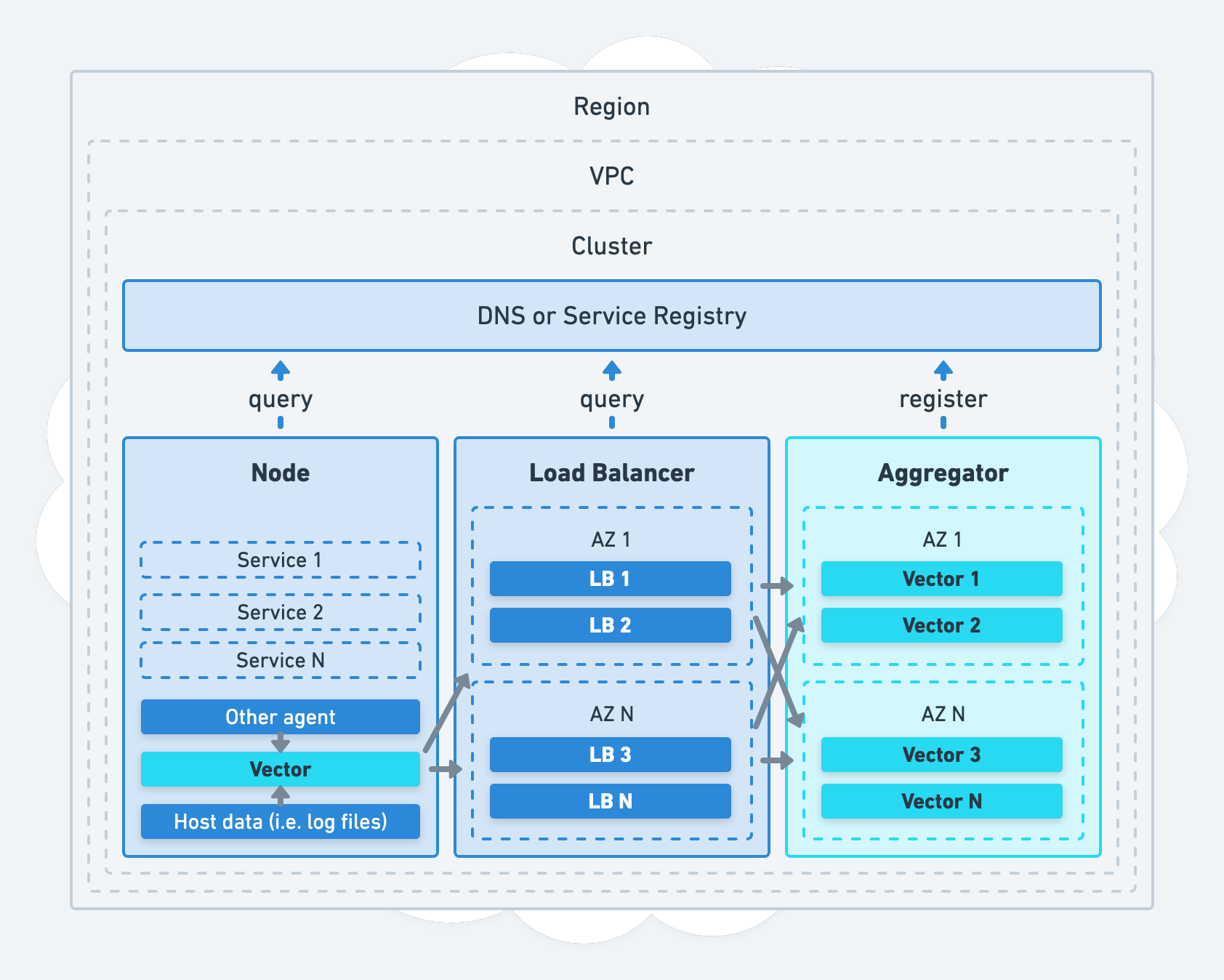
This strategy facilitates routing and load balancing of your traffic, it is how your agents and load balancers discover your aggregators.
Choosing Protocols
When sending data to Vector, we recommend choosing a protocol that allows easy load-balancing and application-level delivery acknowledgement. We prefer HTTP and gRPC due to their ubiquitous nature and the amount of available tools and documentation to help operate HTTP/gRPC-based services effectively and efficiently.
Choose the source that aligns with your protocol. Each Vector source implement different protocols. For example, vector source and sink use gRPC and make inter-Vector communication easy, and the http source allows you to receive data over HTTP. See the list of source for their respective protocols.
Collecting Data
Your pipeline begins with data collection. Your services and systems generate logs, metrics, and traces that must be collected and sent downstream to your destinations. Data collection is achieved with agents, and understanding which agents to use will ensure you’re reliably collecting the right data.
Choosing Agents
In line with guideline 1, it is best to choose the agent that optimizes your engineering team’s ability to monitor their systems. Sacrificing this to use Vector is not recommended since Vector can be deployed in between agents to reduce lock-in. Therefore, Vector should integrate with the best agent for the job and replace others. Specific guidance is below.
When Vector Should Replace Agents
Vector should replace agents performing generic data forwarding functions, such as:
- Tailing and forwarding log files
- Collecting and forwarding service metrics without enrichment
- Collecting and forwarding service logs without enrichment
- Collecting and forwarding service traces without enrichment
Notice that these functions collect and forward existing data, unchanged. There is nothing unique about these functions. Vector should replace these agents since Vector offers better performance and reliability.
When Vector Should Not Replace Agents
Vector should not replace agents that produce vendor-specific data that Vector cannot replicate.
For example, the Datadog Agent powers Network Performance Monitoring. In this case, the Datadog Agent integrates with vendor-specific systems and produces vendor-specific data. Vector should not be involved with this process. Instead, the Datadog Agent should collect the data and send it directly to Datadog since the data is not one of Vector’s supported data types.
As another example, the Datadog Agent collects service metrics and enriches them with vendor-specific Datadog tags. In this case, the Datadog Agent should send the metrics directly to Datadog or route them through Vector. Vector should not replace the Datadog Agent because the data being produced is enriched in a vendor-specific way.
More examples are below.
| Agent | Action | Rationale |
|---|---|---|
| Datadog Agent | Integrate | The Datadog Agent integrates with more systems, produces better data, and seamlessly integrates with the Datadog platform. |
| File Beat | Replace | Vector can tail files with better performance, reliability, and data quality. |
| Fluentbit | Replace | Vector can perform the same functions as Fluentbit with better performance and reliability. |
| FluentD | Replace | Vector can perform the same functions as Fluentd with significantly better performance and reliability. |
| Metric Beat | Integrate | Metric Beat integrates with more systems, produces better data, and seamlessly integrates with the Elastic platform. |
| New Relic Agent | Integrate | The New Relic Agent integrates with more systems, produces better data, and seamlessly integrates with the New Relic platform. |
| Open Telemetry Collector | Integrate | Vector’s built-in OTel support is forthcoming. |
| Splunk UF | Replace | Vector integrates deeply with Splunk with better performance, reliability, and data quality. |
| Syslog | Replace | Vector implements the Syslog protocol with better performance, reliability, and data quality. |
| Telegraf | Integrate | Telegraf integrates with more systems and produces better metrics data. |
Integrating with Agents
If you decide to integrate with an agent, you should configure Vector to receive data directly from the agent over the local network, routing data through Vector.
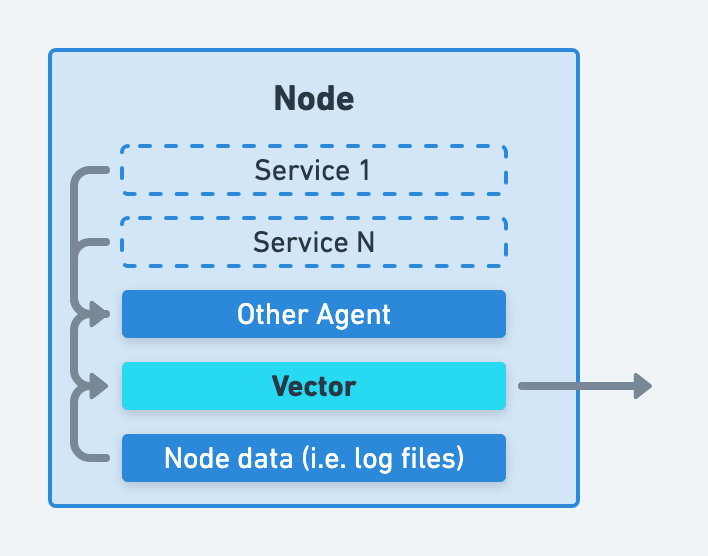
Sources such as the datadog_agent source can be used to receive data from your agents.
Alternatively, you can deploy Vector on separate nodes as an aggregator. This strategy is covered in more detail in the where to process data section.
Reducing Agent Risk
When integrating with an agent, you should configure the agent to be a simple data forwarder, and route supported data types through Vector. This strategy reduces the risk of data loss and service disruption due to misbehaving agents by minimizing their responsibilities.
Replacing Agents
If you decide to replace an agent, you should configure Vector to perform the same function as the agent you are replacing.
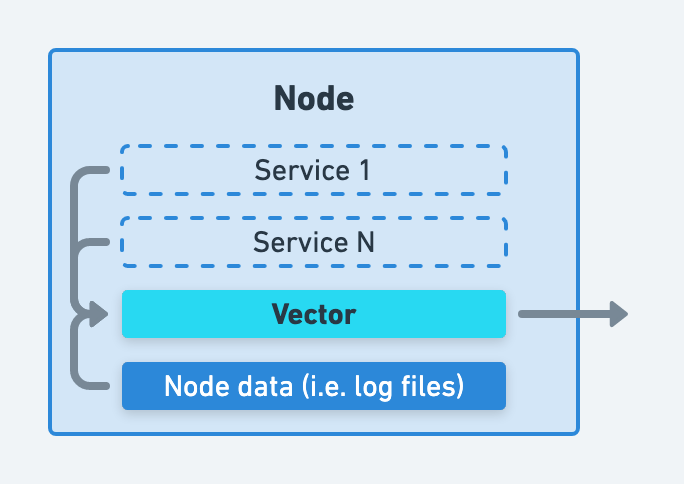
Sources such as the file source, journald source, and host_metrics source should be used to collect and forward data. You can process data locally on the node or remotely on your aggregators.
Processing Data
Data processing deals with everything in between your Vector sources and sinks. It’s a non-trivial task for voluminous data such as observability data, and understanding which types of data to process and where to process it will go a long way in the performance and reliability of your pipeline.
Choosing Which Data to Process
Primitive data types that Vector’s data model supports should be processed by Vector (i.e., logs, metrics, and traces). Real-time, vendor-specific data, such as continuous profiling data, should not flow through Vector since it is not interoperable and typically does not benefit from processing.
Choosing Where to Process Data
As stated in the deployment roles section, Vector can deploy anywhere in your infrastructure. It can deploy directly on your node as an agent for local processing, or on separate nodes as an aggregator for remote processing. Where processing happens depends largely on your use cases and environment, which we cover in more detail below.
Local Processing
With local processing, Vector is deployed on each node as an agent:
This strategy performs processing on the same node that the data originated. It benefits from operational simplicity since it has direct access to your data and scales naturally with your infrastructure.
We recommend this strategy for
- Simple environments that do not require high durability or high availability.
- Use cases that do not need to hold onto data for long periods, such as fast, stateless processing and streaming delivery.
- Operators that can make node-level changes without a lot of friction.
Since this is usually the exception, consider remote processing instead.
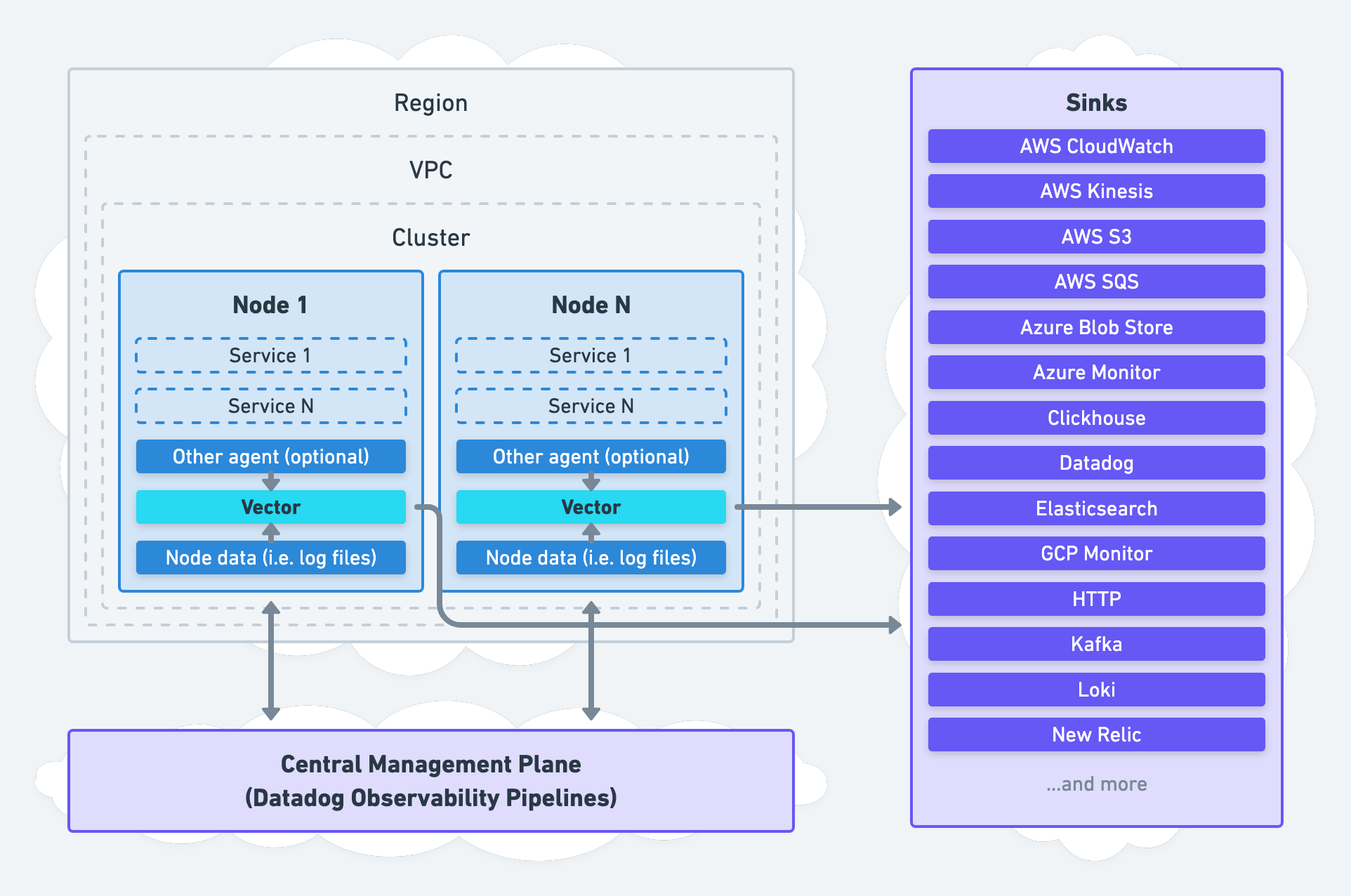
Remote Processing
For remote processing, Vector can be deployed on separate nodes as an aggregator:
This strategy shifts processing off your nodes and onto remote aggregator nodes. We recommend this strategy for environments that require high durability and high availability (most environments). In addition, it is easier to set up since it does not require the infrastructure toil necessary when adding an agent.
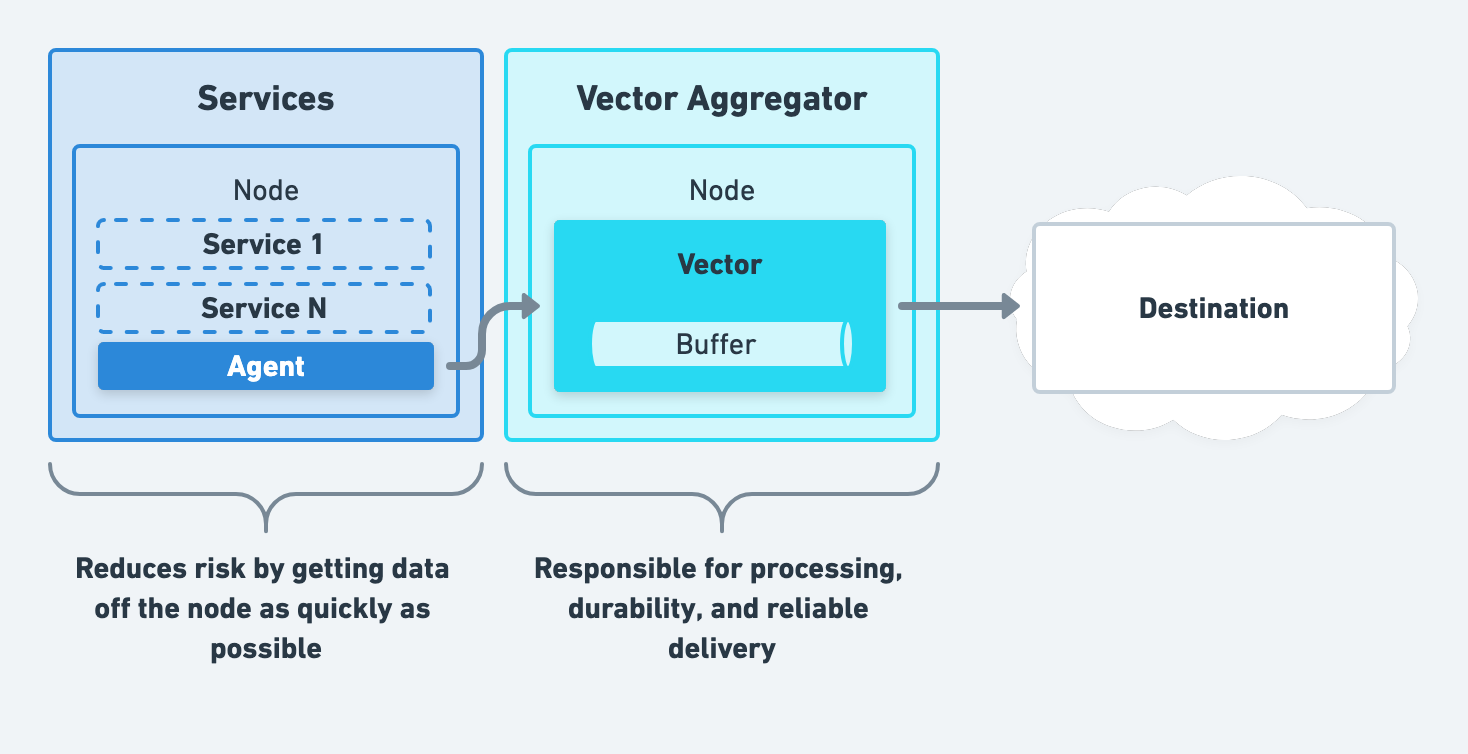
Unified Processing
Finally, you can combine the above strategies to get the best of both worlds, creating a unified observability data pipeline.
We recommend evolving towards this strategy after starting with remote processing.
Buffering Data
Buffering data is essential to a healthy pipeline, but where you buffer data and how you buffer it makes the difference. This section will cover the various ways you can buffer data using Vector and guide you towards sound pipeline buffering.
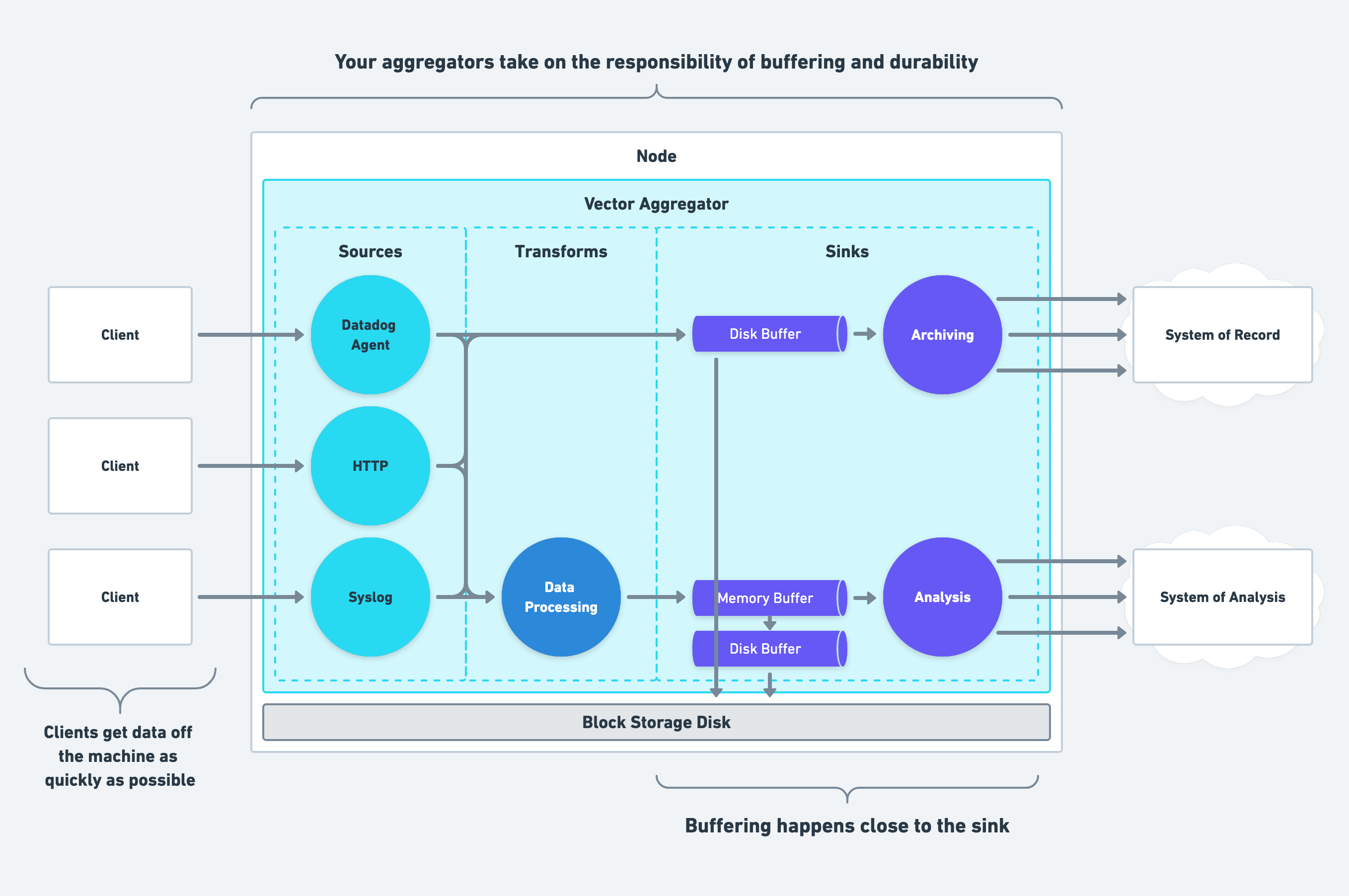
Choosing Where to Buffer Data
Buffering should happen close to your destinations, and each destination should have its own isolated buffer. This design offers the following benefits:
- Each destination can configure its buffer to meet the sink’s requirements. See the how to buffer data section for more detail.
- Isolating buffers for each destination prevents one misbehaving destination from halting the entire pipeline until the buffer reaches the configured capacity.
For these reasons, Vector couples buffers with sinks in its design.
Finally, to follow Guideline 3, your agents should be simple data forwarders and shed load in the face of backpressure. This method reduces the risk of service disruption due to agents stealing resources.
Choosing How to Buffer Data
We recommend using Vector’s built-in buffers. Vector offers reliable, robust buffering that simplifies operation and eliminates the need for complex external buffers like Kafka.
When choosing a Vector buffer type, select the type optimal for the destination’s purpose. For example, your system of record should use disk buffers for high durability, and your system of analysis should use memory buffers for low latency. Additionally, both buffers can overflow to another buffer to prevent back pressure form propagating to your clients.
Routing Data
Routing data is the final piece in your pipeline design, and your aggregators should be responsible for sophisticated routing that sends data to the proper destination. We believe strongly in the power of choice, and you should use your aggregators to route data to the best system for your team(s).
Separating Systems of Record & Analysis
You should separate your system of record from your system of analysis. This strategy allows you to minimize cost without making trade offs that sacrifice their purpose.
For example, your system of record can batch large amounts of data over time and compress it to minimize cost while ensuring high durability for all data. And your system of analysis can sample and clean data to reduce cost while keeping latency low for real-time analysis.
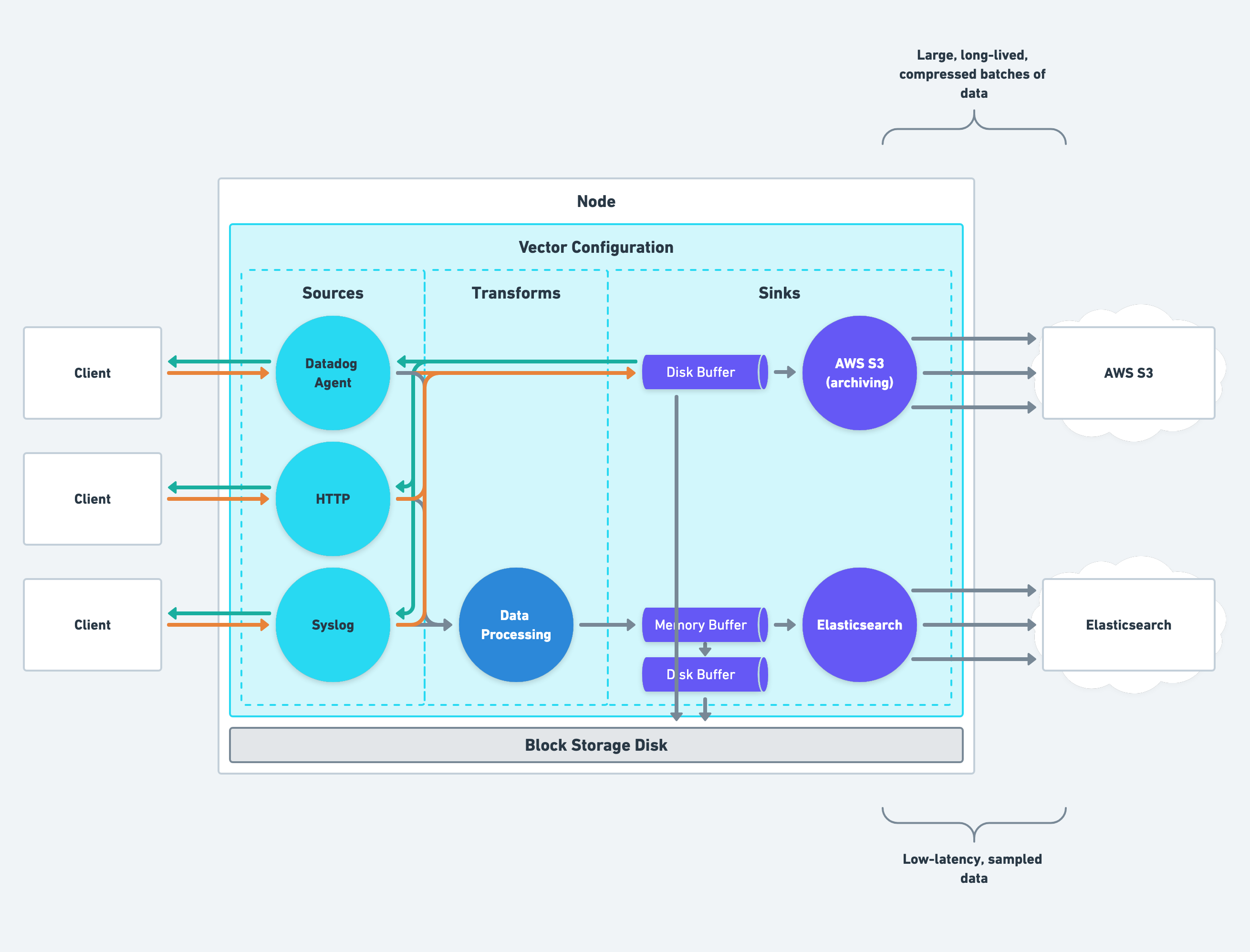
Routing to Your System of Record (Archiving)
Your system of record should optimize for durability while minimizing cost:
- Only write to your archive from the aggregator role to reduce data loss due to node restarts and software failures.
- Front the sink with a disk buffer.
- Enable end-to-end acknowledgements on all sources.
- Set
batch.max_bytesto ≥ 5MiB andbatch.timeout_secsto ≥ 5 minutes and enablecompression(the default for archiving sinks, such as theaws_s3sink). - Archive raw, unprocessed data to allow for data replay and reduce the risk of accidental data corruption during processing.
Routing to Your System of Analysis
Your system of analysis should optimize for analysis while reducing cost:
- Front the sink with a memory buffer
- Set
batch.timeout_secto ≤ 5 seconds (the default for analysis sinks, such asdatadog_logs) - Remove attributes not used for analysis via the
remaptransform - Filter events not used for analysis
- Consider sampling logs with level
infoor lower to reduce their volume