High Availability
Meet the stringent uptime requirements of infrastructure-level software.
Failure Modes
Before making a system highly available, you must understand the various ways it can fail.
Hardware Failures
Disk Failure
Disk failures are treated as process failures since Vector will exit if the disk is unavailable when Vector needs it. Vector will fail to start if the disk is unavailable at boot time, and Vector will exit if the disk is unavailable at runtime.
Vector does not need a disk during runtime unless you’re using a component that requires it, such as disk buffers or the file source and sink.
Node Failure
Mitigate individual node failures by distributing Vector, and its load balancer, across multiple nodes. Front the Vector nodes with a load balancer that will failover when a Vector node becomes unreachable. You should have enough capacity to distribute the tolerated node failure across your available nodes. A good rule of thumb is that no single node should process more than 33% of your data. Finally, automated self-healing should detect and replace unhealthy nodes.
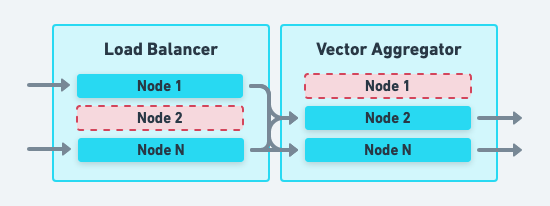
Data Center Failure
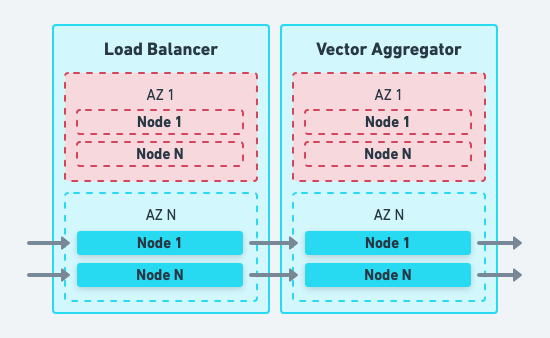
Mitigate data center failures by deploying Vector across multiple Availability Zones. For uninterrupted failover, you should have enough capacity in other Availability Zones to handle the loss of any single Availability Zone. Vector’s high-performance design goal exists to make it economically possible to over-provision in this manner to handle failover seamlessly.
Software Failures
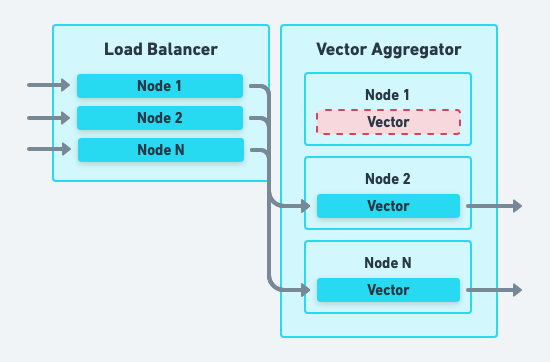
Vector Process Failure
Mitigate Vector process failures similarly to node failures: Vector’s load balancer will failover when a Vector process becomes unreachable. Automated platform-level self-healing restarts the process or replaces the node. This is achieved with a platform-level supervisor, such as a controller in Kubernetes.
Data Receive Failure
Mitigate data receive failures with Vector’s end-to-end acknowledgements feature. When enabled, Vector only responds to the clients when data durably persists. Such as writing the data to the disk buffer or a downstream service.
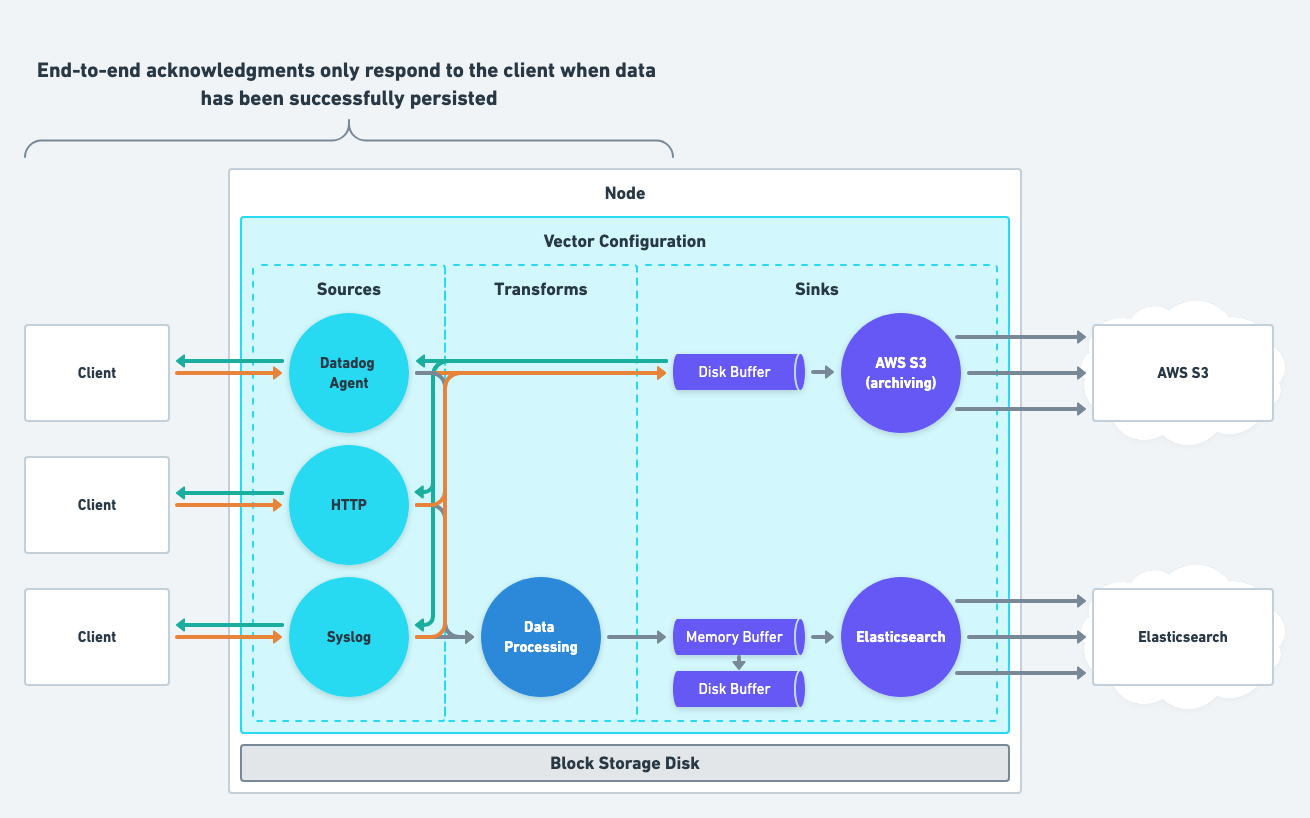
This feature should be paired with disk buffers or streaming sinks to ensure acknowledgements are timely.
Data Processing Failure
Mitigate data processing failures with Vector’s dropped events routing. remap transforms have a dropped output channel that routes dropped events through another pipeline. This flexible design allows the routing of dropped events like any other event.
We recommend routing dropped events immediately to a backup destination to prioritize durability. Then, once data is persisted, you can inspect it, correct the error, and replay it.
The following is an example configuration that routes failed events from a remap transform to a aws_s3 sink:
[sources.input]
type = "datadog_agent"
[transforms.parsing]
inputs = ["input"]
type = "remap"
reroute_dropped = true
source = "..."
[sinks.analysis]
inputs = ["parsing"]
type = "datadog_logs"
[sinks.backup]
inputs = ["**parsing.dropped**"] # dropped events from the `parsing` transform
type = "aws_s3"
dropped channels in other components is forthcoming.Data Send Failure
Mitigate data send failures with Adaptive Request Concurrency (ARC) and buffers.
ARC automatically scales down the number of outgoing connections when Vector cannot send data. ARC minimizes the amount of in-flight data, appropriately applies backpressure, and prevents the stampede effect that often prohibits downstream services from recovering.
Buffers absorb back pressure when a service cannot accept data, insulating upstream clients from backpressure, and durably persisting data. Buffers replay data to the destination upon recovery.
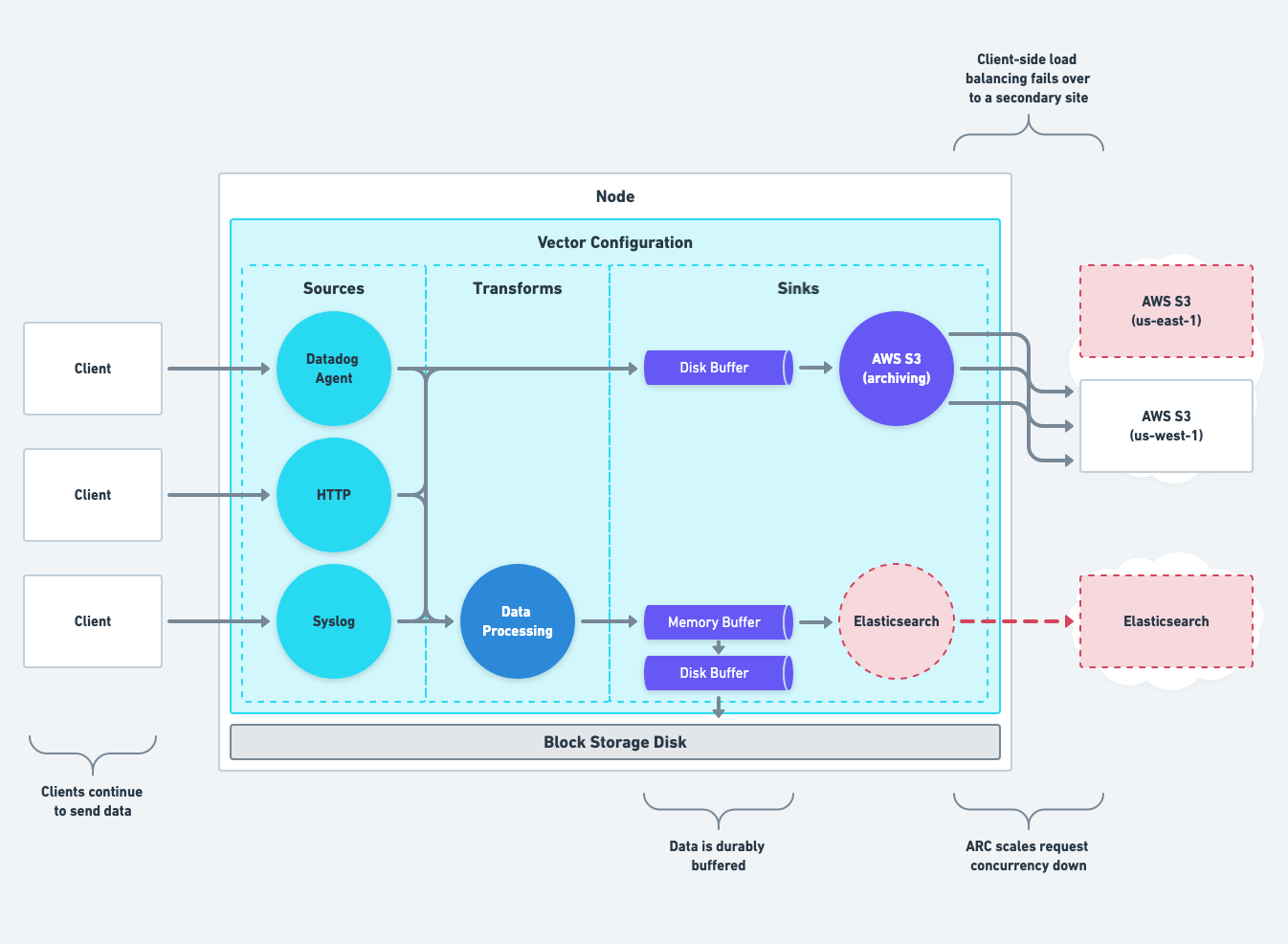
Total System Failures
Mitigate Vector system failures by failing over to intra-network standbys. To recover Vector, standbys should be within the same network to avoid sending data over the public internet for security and cost reasons.
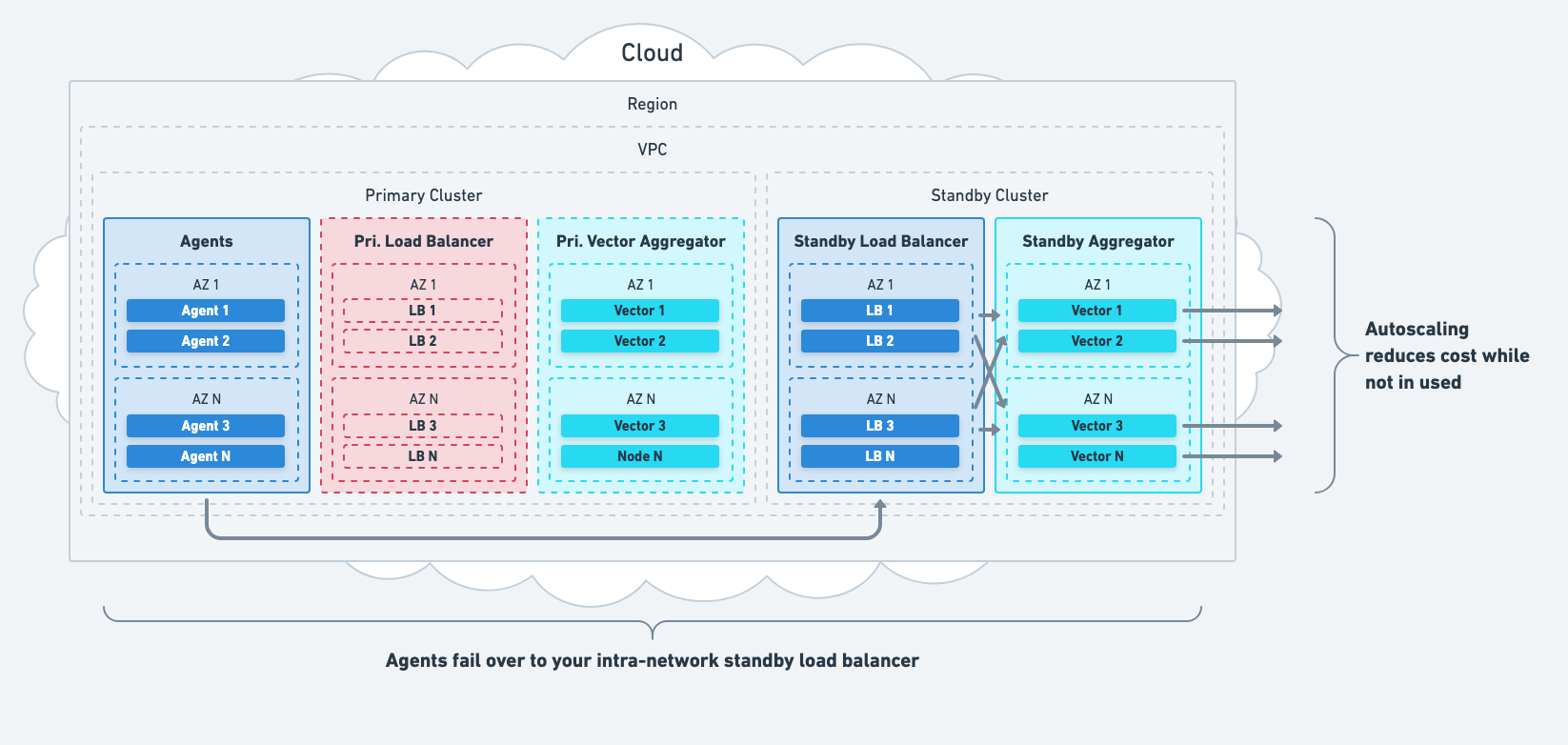
Load Balancer System Failure
Mitigate total load balancer failures by failing over to your standby load balancer. Failover is typically achieved with service discovery or DNS.
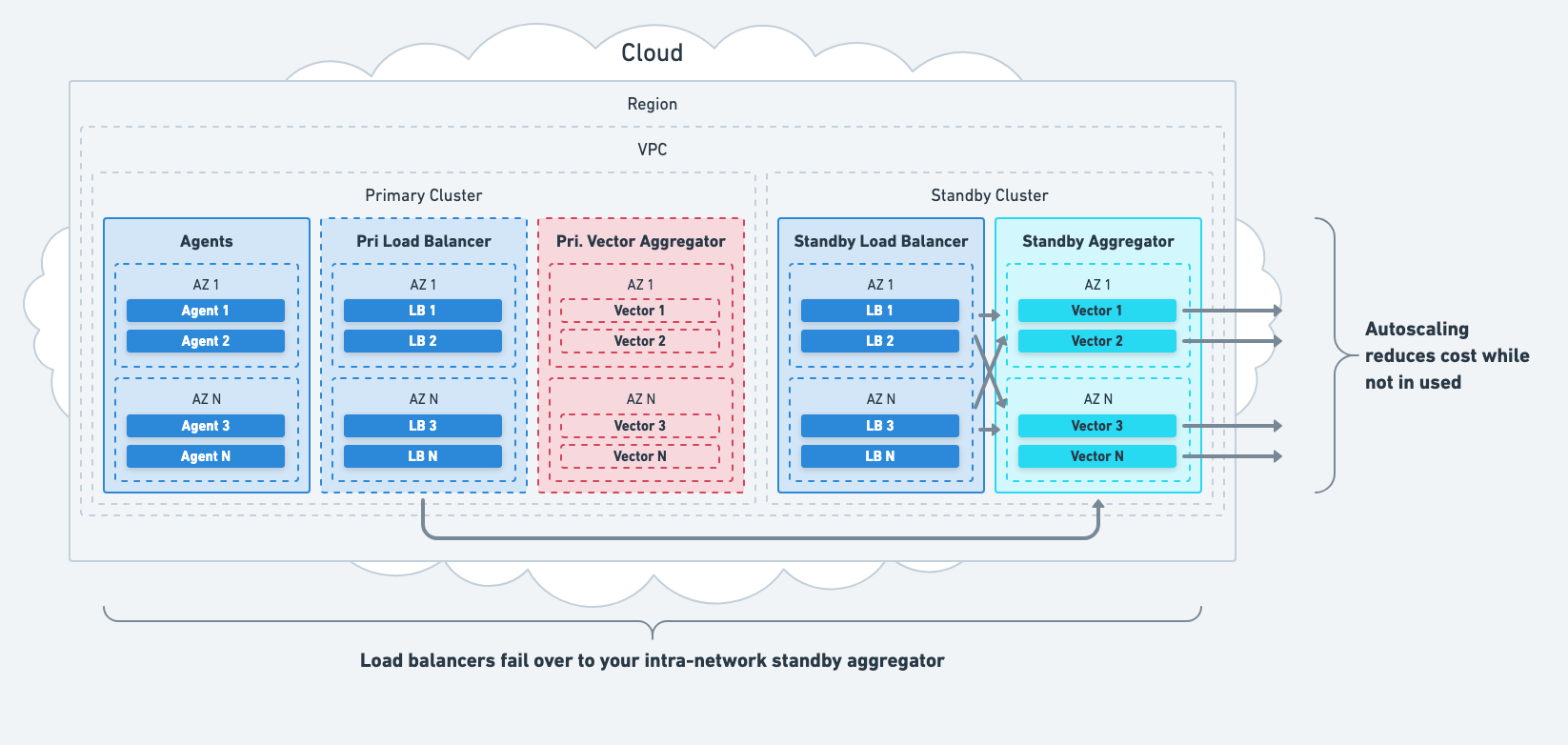
Aggregator System Failure
Mitigate total aggregator failures by failing over to your standby aggregator. Failover is typically achieved with service discovery and DNS.
Strategy
Taking the above failure modes, we end up with the following strategy to achieve high availability.
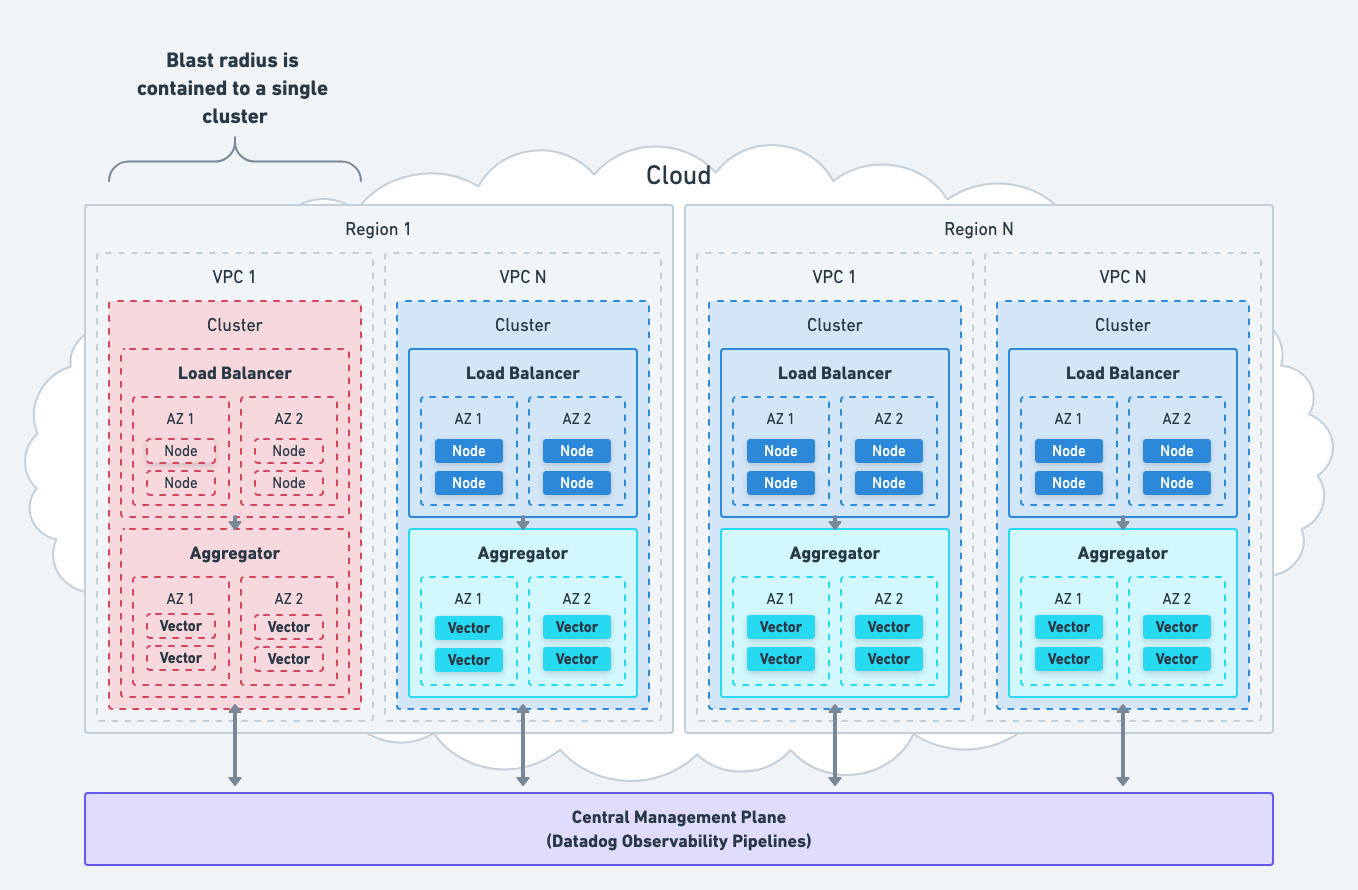
Contain The Blast Radius
Deploy Vector within each network boundary to contain the blast radius of any individual aggregator failure. This mitigates a single point of failure.
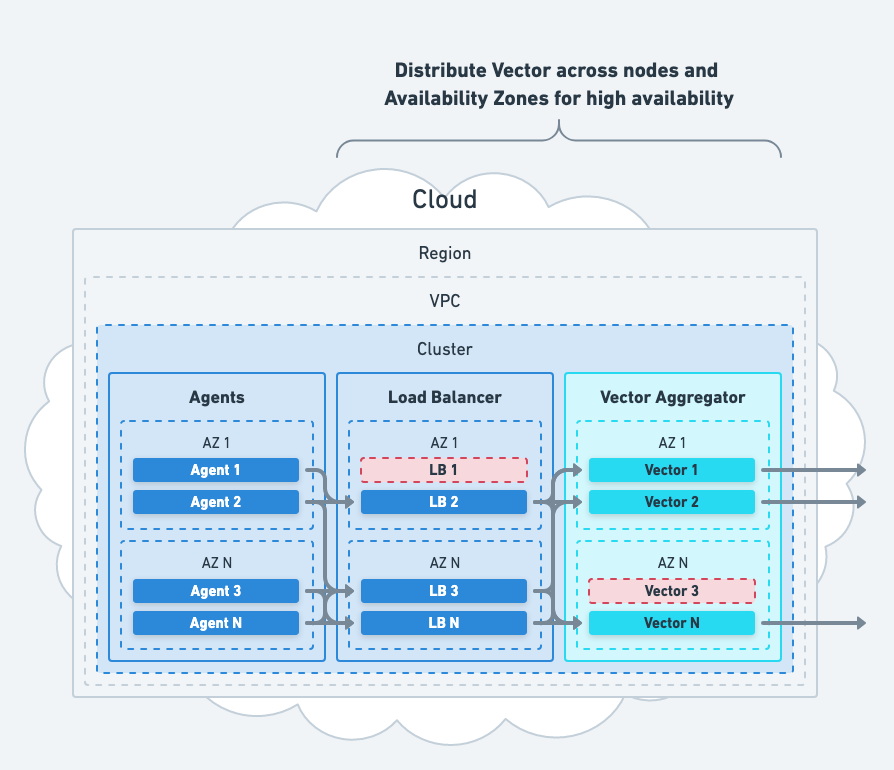
Mitigate Hardware Failures
Mitigate hardware failures by distributing your aggregators and load balancers across multiple nodes and availability zones:
- Deploy at least one node in each availability zone.
- Capacity in your availability zones should handle any single availability zone failure.
These actions mitigate individual node failure and data center failure.
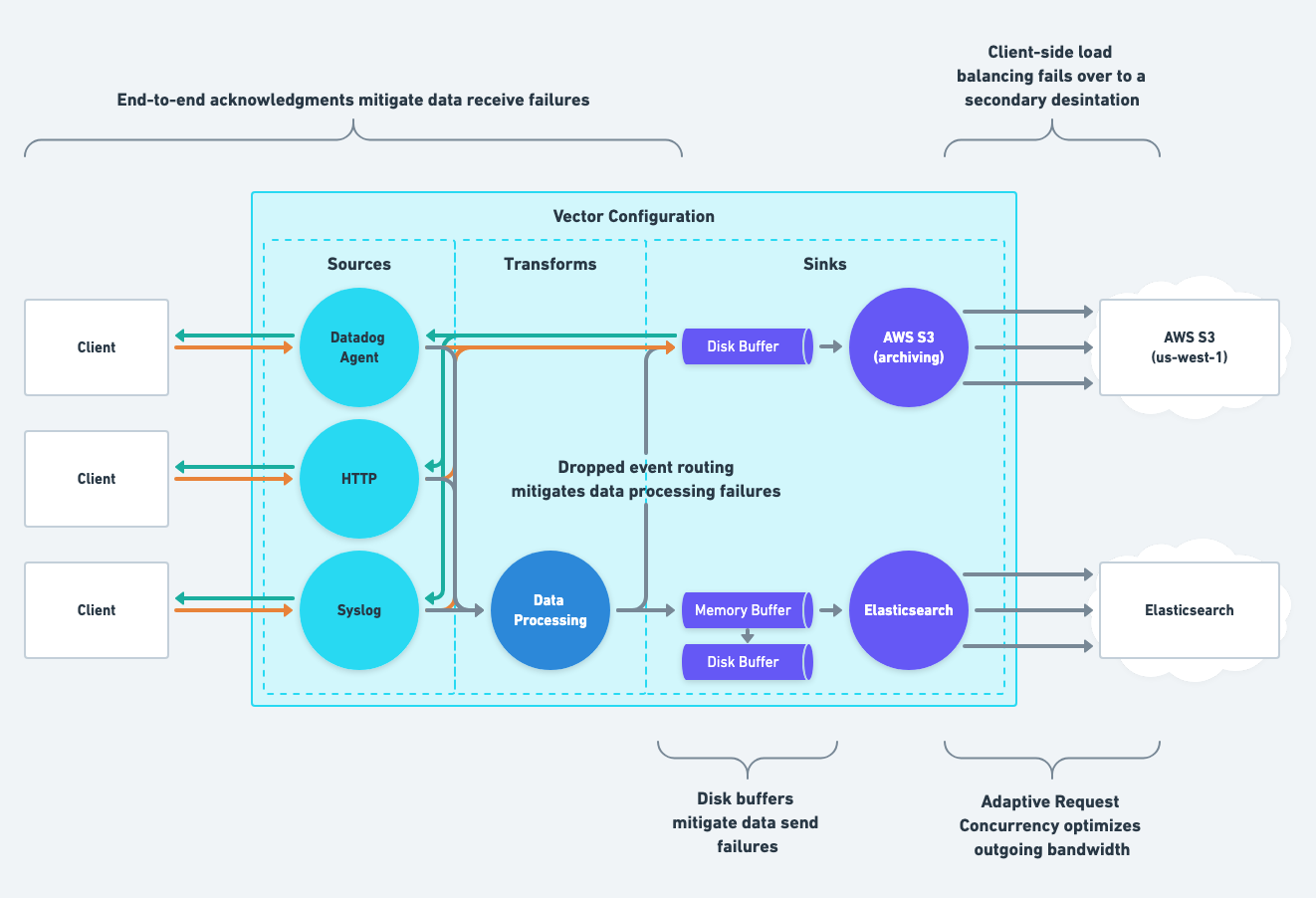
Mitigate Software Failures
Mitigate software failures by configuring your Vector instances as follows:
- Able sources should enable end-to-end acknowledgements.
- Sinks should implement disk or memory buffers that overflow to disk.
- Transforms should implement dropped event routing to your system of record.
These actions mitigate Vector process failures, data receive failures, data processing failures, and data send failures.
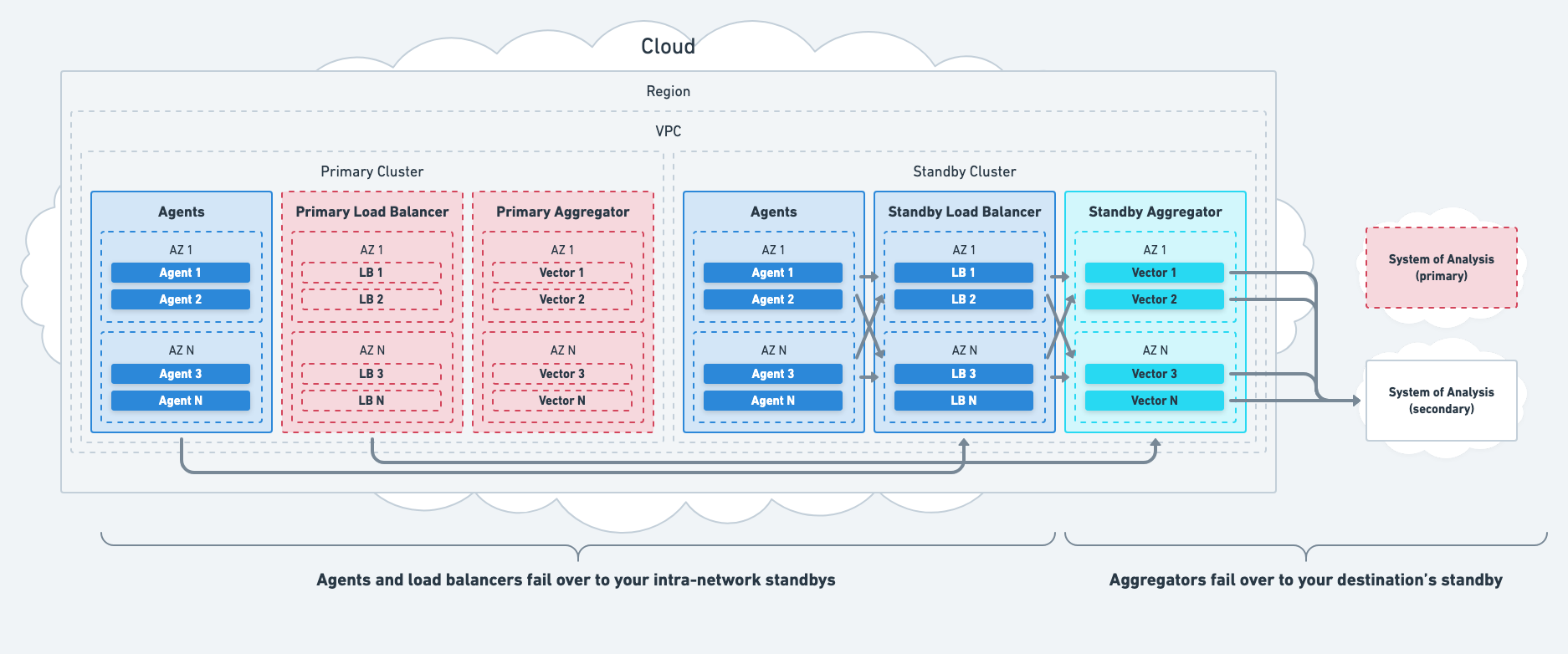
Mitigate Total System Failures
Mitigate Vector system failures by failing over to intra-network standbys. Failover is typically achieved with service discovery or DNS.
- Agents should failover to your standby load balancers.
- Load balancers should failover to your standby aggregators.
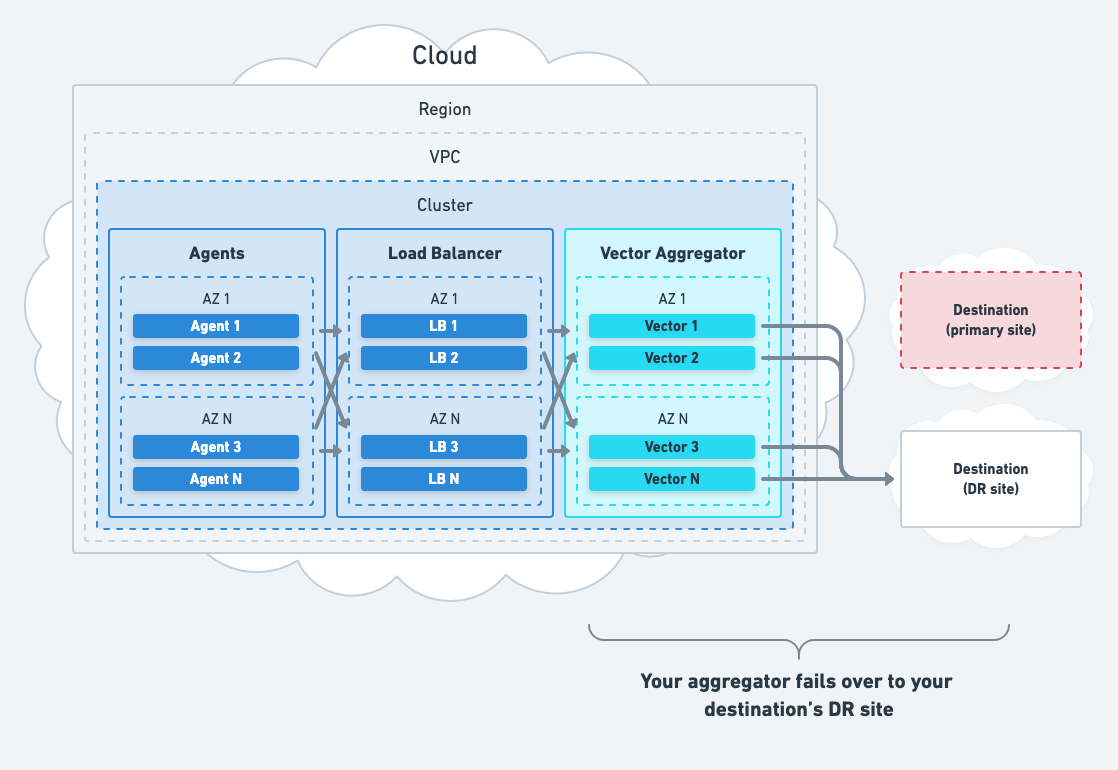
- Aggregators should failover to your standby destinations.
- Autoscaling should be used with your standbys to reduce cost.
These actions mitigate load balancer failure and aggregator failure.
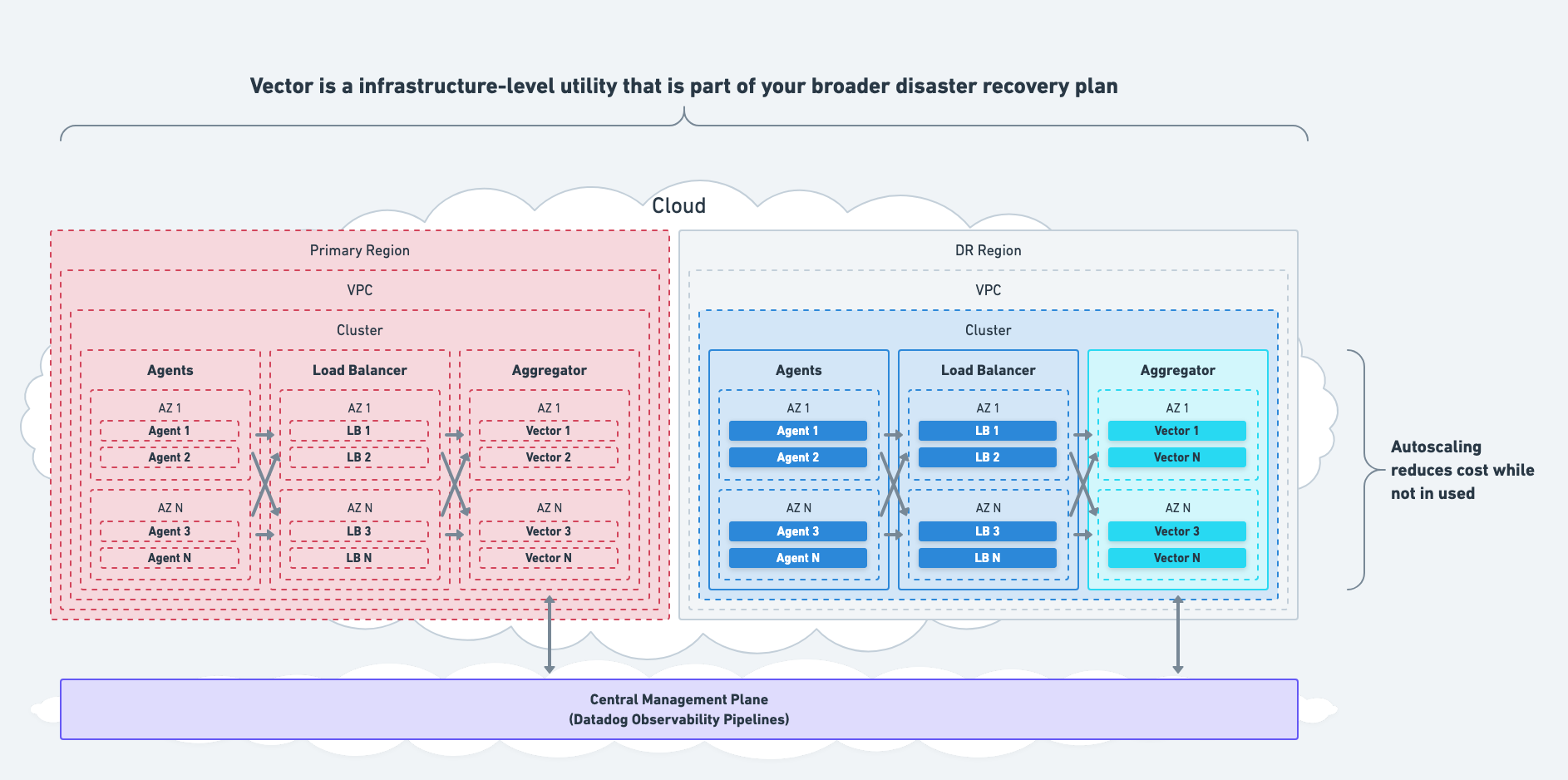
Disaster Recovery & Data Loss
Internal Disaster Recovery
Vector is an infrastructure-level tool designed to route internal observability data. It implements a shared-nothing architecture and does not manage state that should be replicated or transferred to your disaster recovery (DR) site. If the systems that Vector collects data from fail, then so should Vector.
Therefore, if your entire network or region fails, Vector should fail with it and be installed in your DR site as part of your broader DR plan.
External Disaster Recovery
Vector can play an essential role in your disaster recovery (DR) plan for external systems. For example, if you’re using a managed destination, such as Datadog, Vector can facilitate automatic routing data to your Datadog DR site via Vector’s circuit breakers feature.
Enterprise Vector
Datadog Observability Pipelines is Vector’s enterprise offering designed to meet the challenges of deploying and managing Vector at scale. Out-of-the-box monitoring, configuration change management, and expert support simplify operations of Vector in demanding environments.