Rollout
Strategies for rolling Vector out to production environments.
Rollout Strategy
Vector is designed to be deployed anywhere in your infrastructure, making it possible to follow the best practice of deploying within your network boundaries and avoiding a single point of failure. Our rollout strategy takes advantage of this through incremental adoption, minimizing scope, allowing for safe failure, and without the anxiety of switching to a new system.
Incremental Adoption
If you follow our networking recommendations, then you should deploy Vector within each network partition (i.e., cluster or VPC), one at a time.
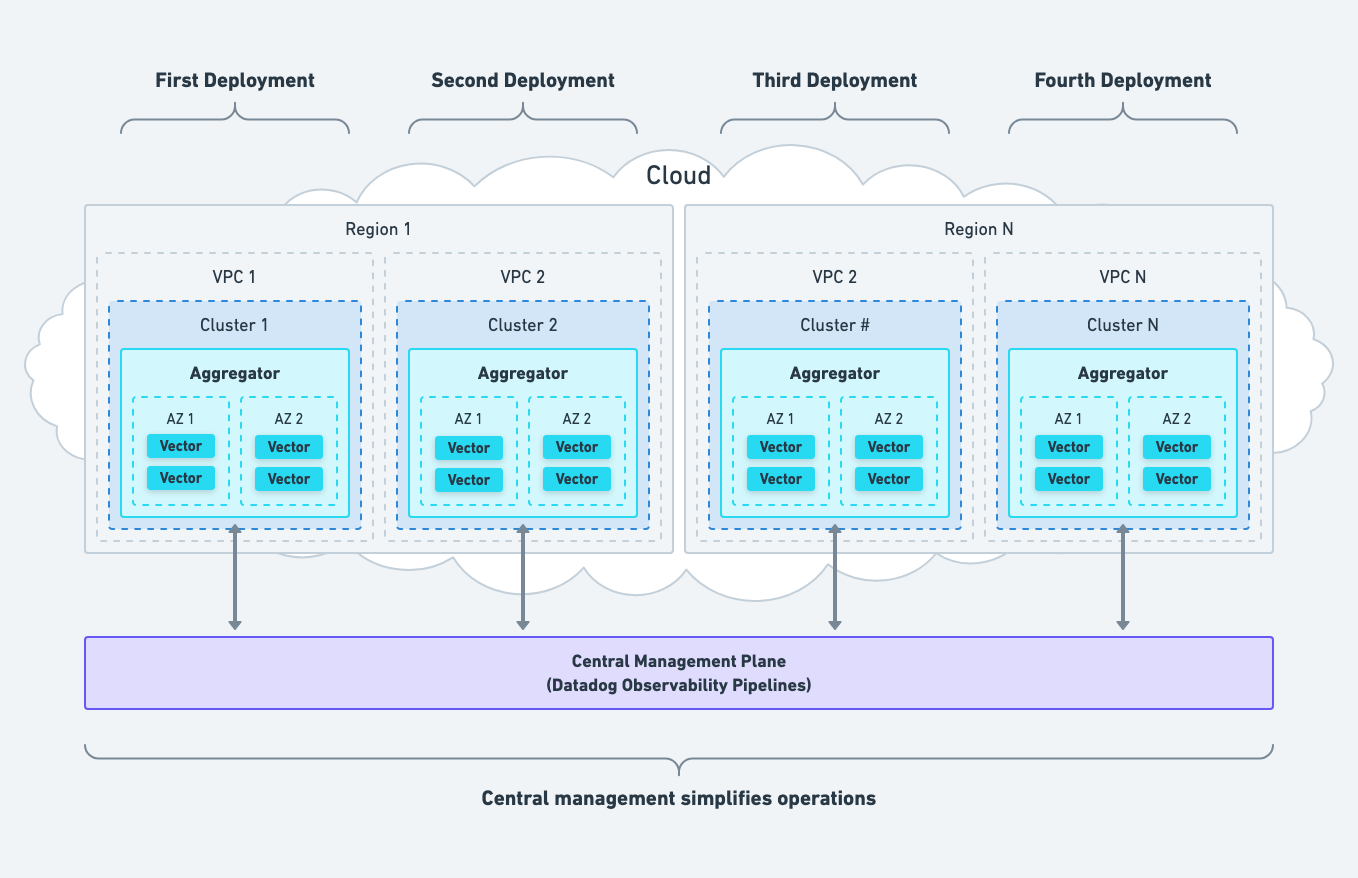
This makes it easy to adopt Vector incrementally, allowing for sustainable progress while building out your observability pipeline.
Minimize Scope
Minimizing scope is the easiest way to ensure success. The scope should be minimized to one network partition and one system at a time. Then, follow the rollout plan for each unit of scope.
Safe Failure
While setting up Vector, it should be allowed to fail without consequence to your business. This means Vector should be operating on a redundant stream of data without disrupting your current production workflows.
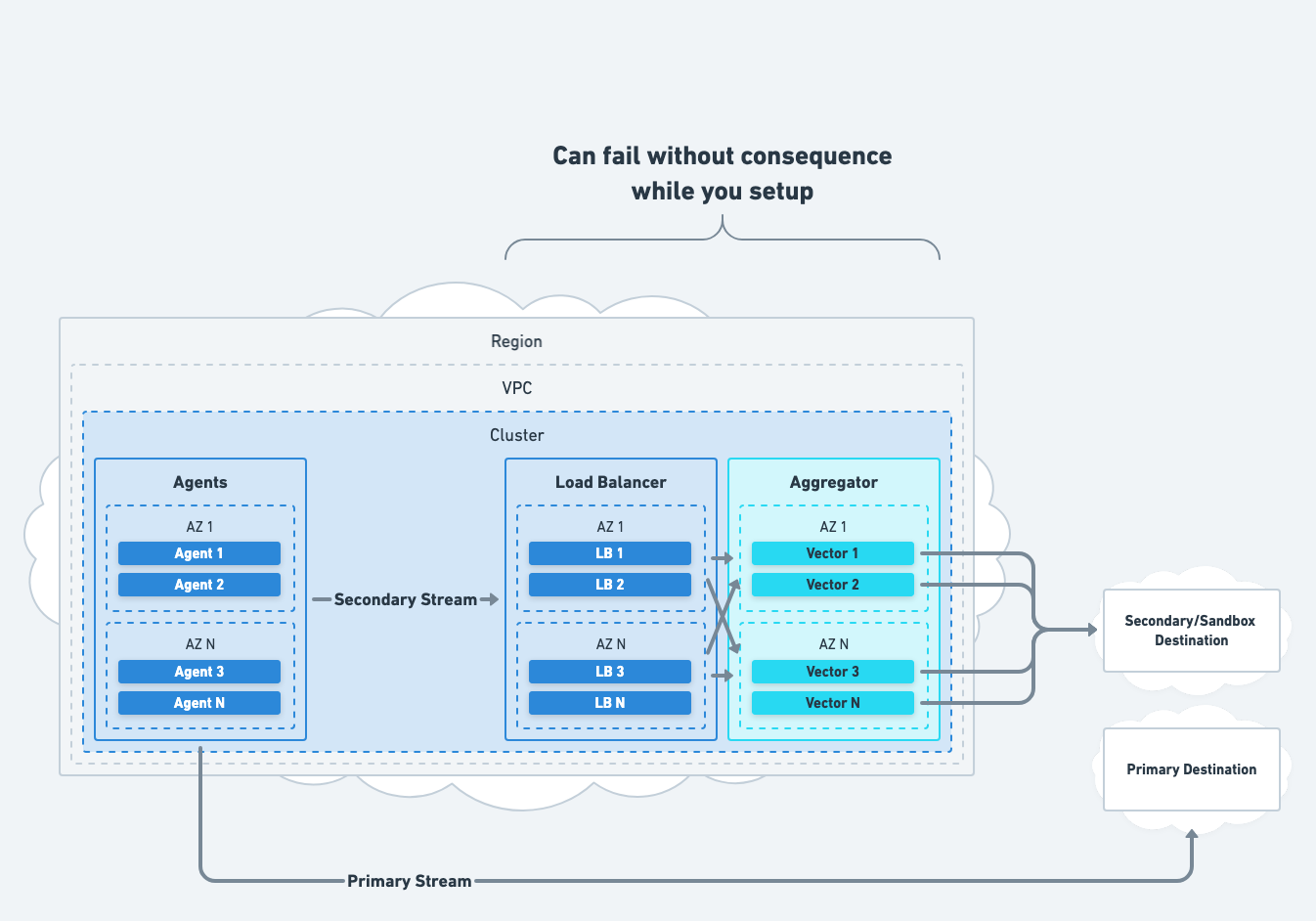
This allows you to gain confidence in Vector before your business depends on it.
Avoid “The Big Switch”
Finally, by the time you cut over to Vector, you should have confidence in its ability. It should already be operating in a production capacity over a sustained period, removing any doubt that Vector will perform reliably in your production environment.
Rollout Plan
1. Deploy a Black Hole
- Identify a single network partition (i.e., cluster or VPC) for your Vector deployment.
- Deploy Vector with a single
blackholesink (the default) within that network partition. - Size and scale Vector’s instances for the conservative estimate of 10 MiB/s/vCPU.
2. Stream a Copy of Your Data
- Stream a copy of data from your agents to Vector. Verify that Vector receives data via the
vector topandvector tapcommands.
3. Configure Vector
- Process your data according to your use cases.
- Integrate Vector with your downstream systems. Verify data within each destination.
4. Size, Scale, & Soak
- Enable autoscaling so that Vector can scale down appropriately.
- Soak Vector for at least 24 hours and monitor performance to ensure production readiness.
5. Cutover
- Safely shut down your agents to allow them to drain data without loss.
- Reconfigure your agents to send data to Vector exclusively.
- Start your agents.
Support
For easy setup and maintenance of this architecture, consider Datadog Observability Pipelines, which comes with support.