Sizing and Capacity Planning
Guidance for single-tenant Vector environments.
Sizing
Sizing your Vector instances largely depends on your Vector workload, and, when possible, we recommend testing your Vector workload to determine your actual numbers. In general, though, most Vector workloads are CPU-intensive and benefit from the same guidance.
Estimations
The following numbers are starting points for estimating your instance sizes. They’re based on our experience working with Vector users but will vary depending on your workload.
| Measurement | Size | Vector Throughput |
|---|---|---|
| Unstructured log event | ~256 bytes | ~10 MiB/s/vCPU * |
| Structured log event | ~768 bytes | ~25 MiB/s/vCPU * |
| Metric event | ~256 bytes | ~25 MiB/s/vCPU * |
| Trace span event | ~1 KB | ~25 MiB/s/vCPU * |
* - These numbers are conservative for estimation purposes.
* - 1 vCPU = 1 ARM physical CPU or 0.5 Intel physical CPU with hyperthreading.
Recommendations
Instance Types
Instances with at least 8 vCPUs and 16 GiB of memory are good units for scaling. Vector can vertically scale and will automatically take advantage of the resources available. Deploy at least one instance per availability zone for high availability. See the capacity planning section for more info.
| Cloud | Recommendations |
|---|---|
| AWS | c6i.2xlarge (recommended) or c6g.2xlarge |
| Azure | f8 or D8plds_v6 |
| GCP | c2 (8 vCPUs, 16 GiB memory) |
CPUs
Most Vector workloads benefit from modern CPUs; we offer the following role-specific recommendations.
- For the agent role, allocate at least 2 vCPUs
- For the aggregator role, allocate at least 4 vCPUs
The ARM64 architecture typically offers better performance for the investment and larger CPU caches improve performance since Vector’s Remap Language compiles to machine code designed to fit into these caches.
| Cloud | Recommendations |
|---|---|
| AWS | Latest generation Graviton (recommended) or Intel Xeon, ≥8 vCPUs |
| Azure | Latest generation Cobalt (recommended) or Intel Xeon, ≥8 vCPUs |
| GCP | Latest generation Intel Xeon, ≥8 vCPUs |
Memory
Due to Vector’s affine type system, memory is rarely constrained due to data processing. Therefore, we recommend 2 GiB of memory per vCPU as a general starting point. Memory usage increases with the amount of sinks due to the in-memory batching and buffering. If you have a lot of sinks, consider increasing the memory or switching to disk buffers. Disk buffers are slower and we recommend increasing memory when possible.
Disks
Sizing disks is only relevant if you’re using Vector’s disk buffers. In this case, we recommend choosing a disk that optimizes for durability. Disk I/O is typically not the bottleneck, and expensive, high-performance disks are unnecessary. Therefore, we recommend generic block storage for its high durability and cost-efficiency.
Provision enough space and throughput to prevent upstream clients from experiencing back pressure during normal operation. For archiving sinks, sinks fronted with a disk buffer, 10 minutes worth of data is usually sufficient.
Note that a disk buffer can become the bottleneck in your Vector topology if its configured throughput is less than the throughput sent to Vector. We recommend configuring disk throughput (if applicable) to at least 2x the expected maximum throughput to give the application adequate headroom. The recommended disks should all have sufficient throughput configurations by default.
For example, if you’re averaging 10 MiB/s/vCPU on an 8 vCPU machine, you should provision at least 48 GiB of disk space (10 MiB * 60 seconds * 10 minutes * 8 vCPUs). This costs $6.00/month, or ~$0.20/day, for AWS EBS io2.
| Cloud | Recommendations |
|---|---|
| AWS | EBS io2, 10m worth of data |
| Azure | Ultra-disk or standard SSD, 10m worth of data |
| GCP | Balanced or SSD persistent disks, 10m worth of data |
Scaling
Vertical Scaling
Vector’s concurrency model automatically scales to take advantage of all vCPUs. There are no configuration changes needed. When vertically scaling, we recommend capping an instance’s size to process no more than 33% of your total volume. This allows for high availability in the event of a node failure.
Horizontal Scaling
Fronting your Vector instances with a load balancer achieves horizontal scaling.
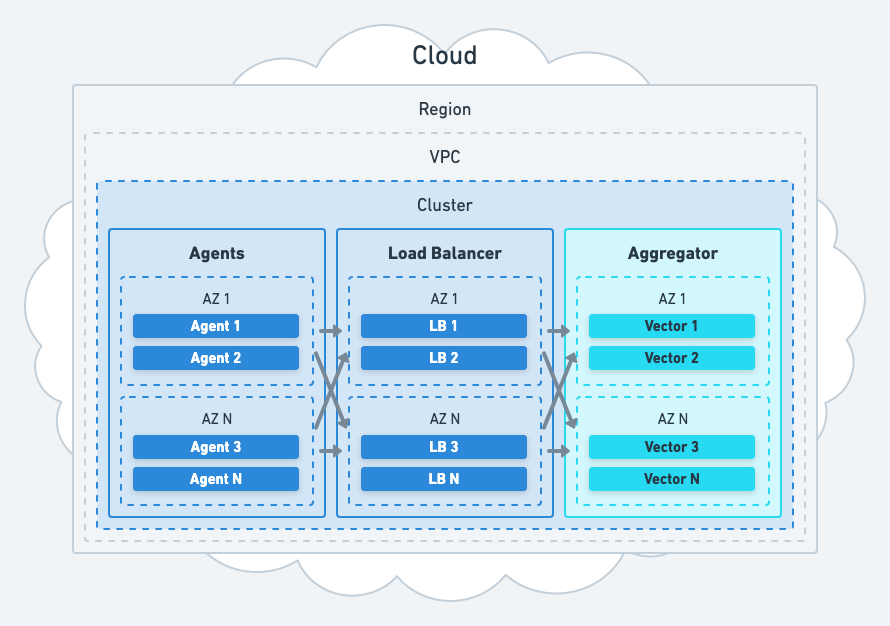
Choosing a Load Balancer
Choose the load balancer you’re most comfortable operating in a highly available manner. When in doubt, use a managed load balancer, such as AWS ALB. These load balancers are highly available and easier to integrate within your cloud environment.
Configuring a Load Balancer
When configuring a load balancer, we recommend the following general settings:
- Choose a protocol between your clients that allows for even load-balancing and application-level acknowledgement. Such as an HTTP-based protocol.
- Enable keep-alive for both clients and servers.
- If you’re using stateful transforms, such as the
aggregateordedupetransforms, use a load balancing algorithm that consistently routes clients to the same server (i.e., the HAProxysourcealgorithm). - If you’re not using stateful transforms, use a load balancing algorithm that evenly distributes traffic (i.e., the HAProxy
roundrobinalgorithm). - Configure load balancers to use Vector’s
/healthAPI endpoint for automatically excluding unresponsive Vector servers. - Ensure that load balancers automatically register all targets as your aggregators scale up and down.
Avoiding Hot Spots
Not all connections are equal; some connections produce much more data making it difficult to evenly load balance traffic across your aggregators. To mitigate this, we recommend the following best practices:
- Use a protocol that allows for even load balancing, such as an HTTP-based protocol. Avoid plain TCP connections for the same reasons.
- Distribute data across multiple connections for easier load balancing.
- Ensure your Vector instances are large enough to handle your highest volume connection to take full advantage of vertical scaling.
- Avoid stateful transformation in aggregators (i.e., the
aggregatetransform), when possible, so that you can use a more fair balancing algorithm.
Autoscaling
For the vast majority of Vector deployments, autoscaling should be based on average CPU utilization. Vector is almost always CPU constrained and CPU utilization is the strongest signal for autoscaling since it will not produce false positives. We recommend the following settings, adjust as necessary:
- Average CPU over 5 minutes with a 85% utilization target.
- A 5 minute stabilization period for scaling up and down.
Capacity Planning
For predicting your capacity, you can use the estimates from above if you don’t have your numbers. Below are a few example scenarios to help with your calculations.
Scenario 1: Unstructured Logs on AWS
A large Splunk enterprise user is looking to reduce their Splunk cost. They produce ~10 TiB/day of unstructured log data across their AWS infrastructure. Based on the above estimations, Vector can process ~10 MiB/s/vCPU (~864 GiB/day/vCPU) of unstructured log data and we end up with the following capacity:
| Resource | Type | Reserved Price | Quantity | Total |
|---|---|---|---|---|
| Instance type 1 | c6g.xlarge | $0.0857/hr | 3 | $6.17/day |
| Disk type 2 | io2 | $0.125/gb/month | 216 GiB72 | ~$0.3/day |
For **$6.20/day ($186/month)** this user could process all of their Splunk data with Vector and reduce their Splunk cost by ~30% on average. We came to the above numbers as follows:
- We reduced the instance type to
c6g.xlargeto have 3 machines for high availability. This gives us a total of 12 vCPUs for a total throughput of ~10.368 TiB/day (10 MiB * 60 secs * 60 min * 24 hours * 12 vCPUs). - We chose 72 GiB to provision the recommended 10 minutes worth of data for each vCPU (
10 MiB * 60 secs * 10 min * 12 vCPUs).
Scenario 2: Tracing on GCP
A large enterprise produces ~25 TiB/day of tracing data across their GCP infrastructure. Therefore, based on the above estimations, Vector can process ~25 MiB/s/vCPU (~2.16 TiB/day/vCPU) of tracing data, and we end up with the following capacity:
| Resource | Type | Reserved Price | Quantity | Total |
|---|---|---|---|---|
| Instance type | c2 (4 vCPUs, 8 GB memory) | $0.101012/hr | 4 | $9.69/day |
| Disk type | Balanced | $0.100/gb/month | 240 GiB | ~$0.8/day |
For **$10.49/day ($314/month)** this user could process all of their tracing data with Vector and reduce their tracing cost. We came to the above numbers as follows:
- We reduced the instance type to
c2with 4 vCPUs to have 3 machines for high availability. - We over-provisioned by one machine to add headroom. This gives us a total of 16 vCPUs for a total throughput of ~34.5 TiB/day (
25 MiB * 60 secs * 60 min * 24 hours * 16 vCPUs). - We chose 240 GiB of disk capacity to provide the recommended 10 minutes of data per vCPU (
25 MiB * 60 secs * 10 min * 16 vCPUs).